科技
设为书签Ctrl+D将本页面保存为书签,全面了解最新资讯,方便快捷。
面对海量增长的高频数据,关系型数据库多次崩溃。在对 DolphinDB、MongoDB 和 KDB+ 进行充分调研对比后,辰钰投资选择了高性能、易学习、同时提供丰富金融函数的时序数据库 DolphinDB。在DolphinDB 的助力下,辰钰投资的量化投研效率得到极大提升。本文将由辰钰投资分享使用DolphinDB的具体实践。
本文作者:辰钰投资 董事长 李栋,董事 陈志凌, 高级工程师 苏虎臣

图1 辰钰的核心策略发展图
目前辰钰投资使用的系统可以轻松实现 Tick-to-trade 微秒级延时,支持多策略、大并发报单,同时支持券商多种风控模式,形成了低延时、高并发、强风控的显著优势。

投研到交易,全流程效率提升
在系统中,我们使用高性能时序数据库 DolphinDB 来帮助提升投研和交易的生产效率。面对每天 20GB 左右的新增数据,DolphinDB 在我们的研究端起到了支撑作用。目前我们的主要业务是数据挖掘和策略研究。在做量化的过程中比如进行因子挖掘、性能计算时,对数据处理的性能要求非常高。在使用 DolphinDB 后,业务效率提升了5-10倍。
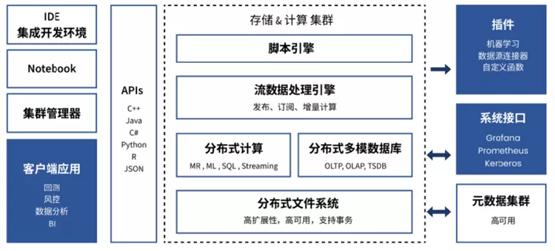
图2 DolphinDB 的系统架构图
首先,我们使用 DolphinDB 进行数据的准备、清洗和挖掘。比如数据清洗。随着数据量的持续增长,难免出现残缺、错误或者重复的数据,那么在进行因子挖掘、策略研究等操作前要先找出并消除这些不符合规范的数据。之前使用的数据清洗工具的性能会随着数据量的增大而下降,无法处理 TB 级别以上的数据。但是通过 DolphinDB 内置的分布式文件系统,合理设计分区,分布式计算与数据清洗性能基本不会随着数据量的增大而下降,目前效率提升超过70倍。
其次,使用 DolphinDB 强大的流数据功能助力指数增强、CTA、套利等方面策略研究。比如中证500指数增强,我们以大量全新的 Alpha 因子为技术核心,同时结合全新改版的交易算法和日内回转交易算法进行选股。在研发环境中,以行情回放的方式模拟实时数据流,通过流数据订阅发布机制和时间序列聚合引擎、响应式状态引擎、横截面引擎等多种流计算引擎,实时高效地计算主买、主卖等量价指标,极大地提升了研发效能。
最后,我们使用 DolphinDB 的分布式计算功能处理高频数据。研发策略时,需要处理大量的逐笔行情数据,之前使用的关系型数据库的性能非常差,远远不能满足我们的业务需求。DolphinDB 的分布式架构可以轻松实现对海量数据的毫秒级快速访问和计算。再比如处理一些股票或者标的,每天要进行几十万、甚至上百万笔的自动交易,关系型数据库很难对此进行处理,但是 DolphinDB 可以快速基于逐笔数据建立策略,极大提升了研发效率。由于团队的技术人员大多熟悉 Python,在实际使用中,我们将 DolphinDB 封装成一个库,可以通过 Python 直接进行访问。仅仅通过一行命令就可以高效、充分地使用 DolphinDB 的海量存储和快速计算功能。
存储大 PK
在使用 DolphinDB 前,我们先后使用过文件系统、MySQL 和 PostgreSQL 存储数据。
之前使用文件系统会先将数据落在本地,然后用 Python 进行计算。但是文件系统在实际应用中存在一些不足。首先,在存储过程中文件系统的 IO 是一个很大的瓶颈。其次,在处理大量数据时,文件系统过于庞大,进行存储、查询等操作费时且费力。同样地,MySQL 和 PostgreSQL 这两个数据库在实际测试中都非常慢。如果要处理的数据量很大,系统甚至会无法工作。
因此,我们想要搭建一套新的系统。主要考虑的数据库有 DolphinDB、MongoDB 和 KDB+。
由于 MongoDB 缺乏函数支持、旧代码改起来比较费劲,KDB+的语言较难学习,整体上手很慢,所以我们放弃了这两个数据库。
反观 DolphinDB,性能比 KDB+更好,语言类 SQL 容易上手,同时提供丰富的金融函数。在低频转向高频的过程中,原来的系统无法处理骤然剧增的数据,但 DolphinDB 是这方面的专家,相较之下新系统的速度可以提升10倍左右。在处理逐笔数据时,相比之前使用过的文件系统,现在的系统效率得到大大提升,并且使用起来也非常方便。此外,DolphinDB 作为一站式数据库,综合了分布式存储、编程建模和高性能计算,可以在研究时快速抽取某些特定的数据,这大大加快了我们的研究进度。
代码“惊魂”
因为之前的很多业务都用 Python 进行相关计算,所以需要将代码转移到 DolphinDB 中。当时发生了一件极其反常的事情——用 Python 和 DolphinDB 分别计算同一个问题,但最后得到了不同的结果!
究竟哪个计算结果是对的?为什么会发生这种情况?会不会影响到实际生产?
带着这些疑虑,我不断进行调试,最后发现原来是Python的脚本出现了编写失误。一个因子有很多计算方法,必须深入到每个因子的具体需求才能对应实现,相应的代码也会较为复杂。当时 Python 的脚本中使用了很多嵌套循环,编写的代码较多较复杂,难免出现脚本编写错误的情况。但是 DolphinDB 的语言非常简洁,实际中不需要那么多循环,只要一行代码就可以全部解决,这大大降低了脚本出错的概率,同时也可以减轻开发人员的压力,有效提升研发的效率。
本文最后
我觉得想要用好 DolphinDB,关键在于理解架构。只有清楚一些技术细节比如分区表的设计原理,才能高效使用工具进行量化投研。刚开始使用 DolphinDB 的时候,我发现使用时系统的反应速度并不是特别快,后来研究了 DolphinDB 的底层架构后,我重新优化了代码,发现速度立刻提升了很多。所以我觉得 DolphinDB 比较考验使用者的水平。使用不同的设计方法解决具体的业务问题,会得到完全不一样的效率。
在此简单分享我司使用 DolphinDB 提升投研效率的经历。希望有更多的朋友了解并使用高性能时序数据库 DolphinDB!
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。
责任编辑:kj005
文章投诉热线:156 0057 2229 投诉邮箱:29132 36@qq.com











