科技
设为书签Ctrl+D将本页面保存为书签,全面了解最新资讯,方便快捷。
2022年1月9日,StarRocks亮相Flink Forward Asia 2021大会开源解决方案专场,StarRocks解决方案架构师谢寅做了题为“双剑合璧:Flink+StarRocks构建实时数仓解决方案”的主题演讲。本文以主讲嘉宾从技术方案的角度,为社区的小伙伴带来最全、最详细的文字版实录回顾!
本文从以下5个方面介绍:
第一部分,实时数仓技术的发展趋势和技术挑战,以及为什么Flink+StarRocks能够提供端到端的极速实时数仓体验。
第二部分,介绍什么是StarRocks,它有哪些技术特点,擅长的场景是什么,以及为什么作为OLAP层的极速分析引擎,它能够很好与Flink技术进行整合。
第三部分,重点介绍联合Flink和StarRocks两大技术栈构建实时数仓的方法论。
第四部分,介绍一些利用Flink和StarRocks构建实时数仓的最佳实践案例。
第五部分,展望了StarRocks在实时数仓方向以及Flink社区贡献等方面的后续规划。
1.实时数仓概述
随着各行各业对数据越来越重视,实时计算技术也在不断的演进。从时效性上来讲,对于小时级或者分钟级的计算已经不能满足客户业务的需要,需求逐渐从时窗驱动,升级到事件驱动,甚至每产生一条数据,都想尽快看到数据。ETL过程也从离线或者微批的ETL,变为Flink擅长的实时流式处理。
数据源上,早先只能支持单一的数据源,整体的数据表现力较差。而当下,人们不仅希望能对单一数据流进行分析计算,还希望能联合多个数据源进行多流计算,为此不惜想尽一切办法,来让数据的表现力更加丰富。
从工程效率的角度上看,技术团队也逐渐意识到,工程代码开发的成本高企不下,更希望能构建自己的平台化IDE工具,让业务人员能基于其上直接进行FlinkSQL的开发。在这些演进的过程也逐渐浮现出一些技术难点亟待解决,比如:
·乱序数据怎么更好的处理?
·通过Watermark之类的手段,是让过去的数据随即失效,还是希望所有的明细数据都能入库?
·多流Join到底应该怎么做合适?
·维表是一次性加载进来,还是放到外存储做热查询,除此之外还有没有其他的技术选择?
·数据处理作业一旦重启,怎么保证在恢复之后还能做到不丢不重的续接消费?
·怎么才能提高整体的业务开发效率,保证业务上线时没有业务中断,更优雅快捷的进行业务逻辑迭代?
在此之外,还有一件事也是业务人员或平台架构师最关注的,那就是通过Flink这么强大的实时计算引擎,费劲千辛万苦好不容易把计算层效率从小时级或者分钟级的延迟提升到了秒级,结果现有的OLAP产品拖了后腿,查询耗费了好几分钟,辜负了计算团队的大量心血。
以上种种,充分证明了极速OLAP+实时计算的重要性,以此我们就可以打造一套端到端的极速实时数仓解决方案,即所谓“双剑合璧”!
谈到数仓,目前业界落地较多的还是Lambda架构,也就是离线数仓和实时数仓分开构建。逻辑分层的形式,也基本形成了业界的共识。业务数据有的是RDBMS采集上来的,有的是日志采集上来的,有的是批量抽取上来的,有的是CDC或者流式写上来的。原始操作层(ODS)基本都是保持数据原貌,然后经过维度扩展、清洗过滤、转换,构建成明细层(DWD)。再往上层走,数据开始做轻度聚合,并有原子指标出现。最后按照主题或者应用的需要产出ADS层里的派生指标或者衍生指标。
企业构建实时数仓,为了让整体的逻辑清晰,通常情况下也会沿用这种分层模式,只不过受限于实时数据到达的先后情况以及业务需要,可能会有些层次的裁剪,不像离线数仓里那么丰富。中间的一些维度信息,可能会同时被离线数仓和实时数仓共享使用。最后将数据送入OLAP产品,供报表系统、接口或者Adhoc查询所调用。
基于前面对数仓典型逻辑分层的探讨,问题也随之而来:
是否有一款OLAP产品能够很好的和Flink结合,满足持续的秒级的数据摄入和极速分析查询能力?
答案是一定的,StarRocks的定位正是要提供极速分析查询能力,来适应各种各样的OLAP场景。
2.StarRocks是什么
这是StarRocks的宏观架构图。
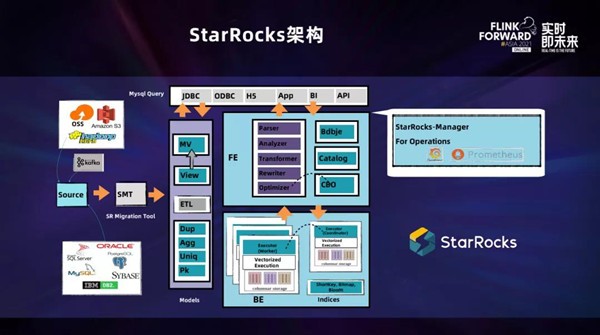
从左边我们可以看到常见的Kafka、分布式文件系统、传统关系型数据库,都可以作为StarRocks的数据源。
StarRocks提供了4种模型:
·如果业务场景只涉及数据的持续Append,可以选择Duplicate明细模型,在其上可以实时构建物化视图加速DWS层查询;
·如果业务场景不关注明细的下钻,StarRocks还有Aggregate聚合模型表,相当于数据直接秒级打入DWS层,满足高并发的聚合指标查询;
·对于ODS层做业务库数据还原时,若涉及到数据更新的场合,可以采用Unique模型,利用Flink的Append流Sink数据进来,完成ODS数据去重和更新;
·另外,StarRocks最新2.0版本提供的PrimaryKey主键模型,比Unique模型查询性能快3倍以上,内置了OP字段来标记Upsert/Delete操作,并且能够很好的吻合Flink的Retract回撤流语义,聚合计算不必非要开窗转为Append流来Sink,进一步增强了FlinkSQL的表现力。
StarRocks还提供了逻辑View和物化视图,提供了更丰富的建模能力。
在上图的右侧是StarRocks的物理架构,整体还是非常简洁的,主要就是两种角色:FE前端节点和BE后端节点。
·FE负责查询规划、元数据管理、集群高可用,并包含CBO优化器,为分布式多表关联和复杂Adhoc查询提供最优的执行规划。
·BE节点承载了列式存储引擎和全面向量化的执行引擎,保障在OLAP分析场景中提供极速查询体验。
·对上层应用提供MySQL连接协议,可以用MySQL客户端轻松连入进行开发和查询,和主流BI工具有很好的兼容性,也可以服务于OLAP报表和API封装。
3.StarRocks擅长哪些场景
基于StarRocks的4种模型,可以提供明细查询和聚合查询,能够应对OLAP报表的上卷和下钻,比如在广告主报表场景应对高并发点查询。
StarRocks基于Roaring Bitmap提供了Bitmap数据结构,并配套有集合计算函数,可以用于精确去重计算和用户画像的客群圈选业务。在实时方面,StarRocks可以用于支撑实时大屏看板、实时数仓,秒级延迟的呈现业务原貌和数仓指标。
最后,基于CBO优化器,StarRorcks在OLAP场景下有很好的多表关联、子查询嵌套等复杂查询的性能,可以用于自助BI平台、自助指标平台和即席数据探查等自助分析场景。
StarRocks能够用于构建实时数仓,得益于他的三种实时数据摄入能力:
·可以直接消费Kafka的消息。
·可以借助Flink-connecor实现Exactly-once语义的流式数据摄入。
·另外,结合Flink-CDC和PrimaryKey模型,可以实现从TP库Binlog实时同步Upsert和Delete等操作,更好的服务于ODS层业务库还原。
利用Flink-Connector-StarRocks插件,可以实现从TP库Binlog实时同步Upsert和Delete等操作,更好的服务于ODS层业务库还原。配套的SMT(StarRocks Migration Tool)工具,可以自动映射Flink中的TP库Source和StarRocks库的Sink建表语句,使得基于FlinkSQL的开发工作变得简单便捷。
另外,Flink-Connector更重要的功能是提供了通用Sink能力,开发者把依赖加入后,无论是工程编码还是FlinkSQL都可以轻松Add Sink,保障数据秒级导入时效性。
结合Flink的Checkpoint机制和StarRocks的导入事务标签,还可以保障不丢不重的精准一次导入。
StarRocks的实时物化视图构建能力,结合Flink-Connector的持续增量数据导入,可以在流量类指标计算的建模中,实现DWD明细数据导入完成的同时,DWS聚合指标也同步增量构建完成,极大提升聚合指标产出效率,缩短分层ETL的旅程。
StarRocks提供的Replace_if_not_null能力比较有意思,正如语义所述,只要插入的数据不是null,那么就可以去替换数据。
如图所示,右侧是个建表示例,里面维度列为日期和Uid,其余3列中SRC表示数据源,另外带了v1,v2两个Metric;

通过2个Insert语句我们可以看到,来自2个Kafka主题的数据源的数据,轻松的实现了同时写入一张表的不同列。因此,这个功能提供了两种实时数仓能力:
1)Join on Load,也就是在导入的过程中,基于StarRocks来实现流式Join。
2)部分列更新能力。
StarRocks为了支持更好的Upsert/Delete,提供了PrimaryKey表模型。
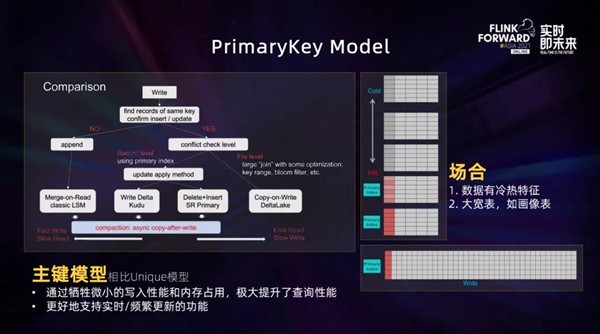
如上图所示,最左侧是经典的LSM模型,也就是Merge-on-Read的形式。这种模型写入时不用去判断既有键位,对写友好,但读取时需要Merge合并,所以对读取数据不友好。
而最右侧是Copy-on-Write的模型,典型的产品就是DeltaLake。这种模型和LSM正好相反,有比较好的读效率,但是对于写入不是很友好。
比较平衡读取和写入的,就是上图中间的两种Record级别冲突检查的模型,Kudu的Write Delta和StarRocks的Delete+Insert模型。
由于维护了内存表,PrimaryKey模型更适合冷热特征明显的场合,对热数据频繁的更新和删除更友好;
另外非常适合PrimaryKey较少的表(如用户画像的宽表),虽然列很多,但是主键其实只有UUID这种字段。
StarRocks早期的Unique模型就是采用了最左边的LSM模型,因此查询效率较差,并且对于Delete不友好,结合Flink开发应用时,只能使用Append流进行Sink。
StarRocks 2.0版本中新增加的PrimaryKey模型,提供了软删除字段,通过在内存中维护最新数据,使得查询时避免了Merge的过程,从而极大提升了查询性能,并且既可以使用Append流也可以使用Retract流进行Sink,丰富了与Flink结合时的应用场景。
4.构建实时数仓的具体方法
众所周知,在按照逻辑分层自下而上的构建实时数仓时,多流Join是有一定的技术门槛的。传统的实时计算引擎如Storm、Spark Streaming在这方面做的都不是很好。而Flink其实提供了很多通用的解决方法,如:
·基于MapStat做状态计算,或者BroadcastStat将维度缓存广播出去;
·用Flink关联外部热存储,如HBase/Redis等;
·一些相对稳定、更新频率低的维度数据或者码表数据,可以利用RichFlatMapFunc的Open方法,在启动时就全部加装到内存里;
不限于以上这些,其实Flink已经在维度扩展上,给了开发者很多可以落地的选择。然而有了StarRocks,我们会有更多的想象空间。
比如利用前面介绍的Replace_if_not_null的能力,开发者可以实现多个数据源稀疏写入宽表的不同列,来实现Join-on-Load的效果。
另外StarRocks强悍的CBO优化器在多表关联查询能力方面也表现优异,如果数据量不大或者在查询并发不高的场景,甚至可以把Join的逻辑下推到OLAP层来做,这样可以释放掉Flink上的一些构建负荷,让Flink专注于清洗和稳定的数据导入,而多表关联和复杂查询等业务逻辑在StarRocks上进行。
不仅如此,还可以结合Join-on-Load和Join on StarRocks的两种形式,也就是稀疏写入有限张表,通过表之间做Colocation join策略,保证有限的表之间数据分布一致,做Join的时候没有节点间Shuffle,在上层构建逻辑View面向查询。
双剑方案1.微批调度

Flink清洗导入Kafka的日志或者用Flink-CDC-StarRocks读取MySQL Binlog导入StarRocks,ETL过程中埋入批次处理时间,采用外围调度系统,基于批次处理时间筛选数据,做分钟级微批调度,向上构建逻辑分层。
这种方案的主要特点是:StarRocks作为ETL的Source和Sink,计算逻辑在StarRocks侧,适用于分钟级延迟,数据体量不大的场景。
双剑方案2.Flink增量构建
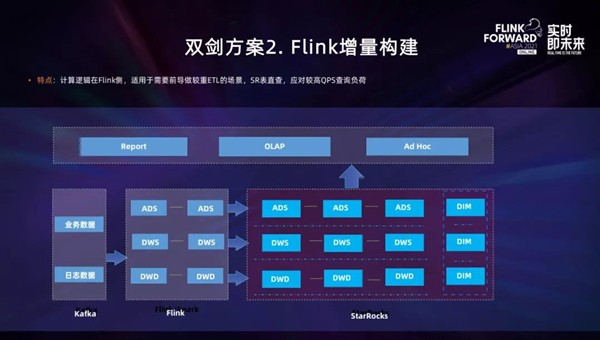
实时消息流通过Kafka接⼊,采用Flink进⾏流式ETL、多流Join、增量聚合等,在内存中完成分层构建,然后将相应的数据,层对层的通过Flink-connector写出到StarRocks对应表内。各层按需面向下游提供OLAP查询能力。
该方案的主要特点是:计算逻辑在Flink侧,适用于需要前导做较重ETL的场景,StarRocks不参与ETL,只承载OLAP查询,应对较高QPS查询负荷。
双剑方案3.StarRocksView视图
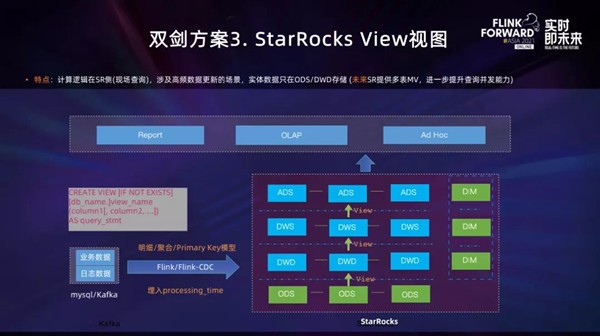
Flink清洗导入Kafka的日志或者用Flink-CDC-StarRocks工具读取MySQL Binlog导入StarRocks;根据需要选用明细、聚合、更新、主键各种模型,只物理落地ODS和DIM层,向上采用View视图;利用StarRocks向量化极速查询和CBO优化器满足多表关联、嵌套子查询等复杂SQL,查询时现场计算指标结果,保证指标上卷和下钻高度同源一致。
该方案主要特点是:计算逻辑在StarRocks侧(现场查询),适用于业务库高频数据更新的场景,实体数据只在ODS或DWD存储(未来StarRocks提供多表Materialized Views,将会进一步提升查询性能)。
5.最佳实践案例
前面我们介绍了一些联合Flink和StarRocks构建实时数仓的几种方法论,下面我们来看4个实际的客户案例。
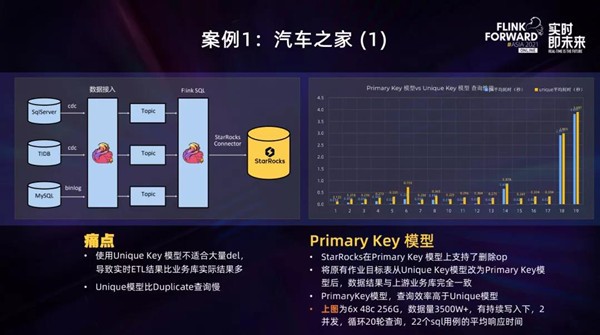
汽车之家目前在智能推荐的效果分析、物料点击、曝光、计算点击率、流量宽表等场景,对实时分析的需求日益强烈。经过多轮的探索,最终选定StarRocks作为实时OLAP分析引擎,实现了对数据的秒级实时分析。
在数据处理流程上,SQLServer、MySQL、TiDB等数据源,通过CDC打入多个Topic主题,用FlinkSQL进行ETL清洗和聚合计算,然后通过Flink-Connector导入StarRocks。早期选择的Unique表模型,由于业务有很多Delete操作,而Merge-on-Read的模型对Delete支持不好,如果只做Update而不做Delete,会造成结果数据比业务库多的问题。
最新的PrimaryKey模型支持了OP字段(更新/删除操作),改为PrimaryKey模型后,数据结果与上游业务完全一致。
上图右侧是在硬件配置6x 48c 256G、数据量3500W+、有持续写入情况下,22个SQL用例的测试情况,查询性能也比Unique模型有大幅提升。
在合理的选型和建模之后,汽车之家在实时平台IDE上也做了很多工作,开发运维人员可以在页面里进行DDL建表,FlinkSQL开发,作业的起停、上线管理等工作。结合Flink-Connecotor,可以直接通过FlinkSQL将加工后的数据导入StarRocks,完成端到端的实时平台集成。
另外,利用StarRocks提供的200多个监控Metric,汽车之家用Prometheus和Grafana等组件做了充分的可视化监控,即时查看集群的统计指标,把握集群的健康状态。

第2个案例,顺丰科技的运单分析场景实践。在2021年双11大促活动中,运单分析场景应对了15w TPS消息体量的实时数据导入和更新。整体的处理流程如图所示,多个业务系统中的数据源打到几个Source Kafka,用Flink来对数据进行加工、字段补充、重新组织,然后整理后的数据打到若干个Sink Kafka主题,最后利用前面介绍的Join-on-Load的形式,将多个数据源的数据,稀疏的写入宽表的不同列,以此来实现宽表拼齐的过程。
在具体使用上,顺丰科技将运单的数据根据更新的频度,划分为了2张宽表,按照相同的数据分布做成Colocation组,保证Join的时候没有额外的节点Shuffle。一张表涉及的更新较少,命名为公表。另一张表涉及的更新较多,命名为私表。
每个子表都利用了Replace_if_not_null的部分列更新的能力,合理的设计了维度和聚合指标,并引入了Bloom Filter索引加速筛选的效率,用日期做范围分区,用订单号做数据分布,配置了动态分区,自动淘汰冷数据。对外通过逻辑View的形式关联成一张宽表,底层是以现场Join的形式,整体面向业务提供查询服务。
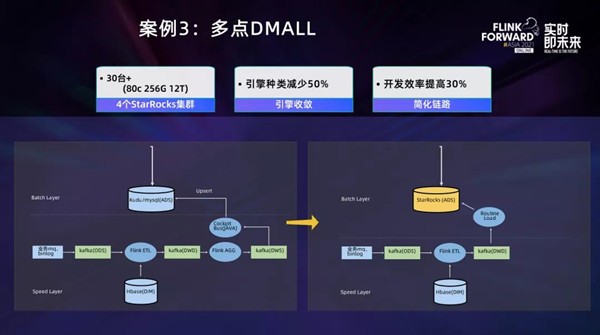
第3个案例是来自多点DMALL的实时数仓实践。实时更新场景主要对实时监控经营的各项指标进行分析,如当前时间段内的GMV、下单数量、妥投数量、指标达成、对比、环比等指标分析,为客户的经营决策提供更具时效性的参考依据。
早期,针对数据为实时(秒级)更新的场景,主要使用Impala on Kudu引擎,采用Lambda架构,基于相同的主键,将流式的预计算的结果数据、批计算的结果数据,基于相同的主键进行Merge。
这个Case早期的架构如左图所示,ODS、DWD、DWS等分层在Kafka里承载,ADS层在Kudu/MySQL里,维表放在HBase里,采用Flink查询外表热存储的形式实现维度数据和事实消息的关联。如右图所示,经过梳理和改造,顺丰科技将DWD到DWS的聚合处理从Flink下沉到OLAP层,用StarRocks替换了Kudu,简化了预聚合链路,提升了开发效率。
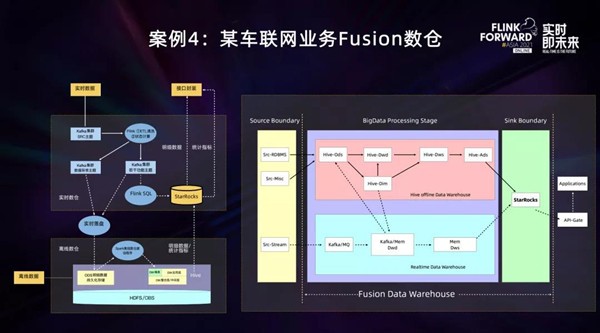
第4个案例是来自一个某车联网企业的Fusion数仓建设。随着新能源汽车的普及,车联网IOT数据的实时接入分析的需求也越来越多。
业务逻辑如左图所示,传感器上报的仪表、空调、发动机、整车控制器、电池电压、电池温度等1000+传感器Metric要通过Flink做实时ETL清洗,同时要完成功能主题实时分拣、数据质量实时报告,最终满足于时序数据综合分析和可视化展示。技术上,大量采用Flink.Jar的工程代码开发,对于某些码值还涉及到Flink多流Join及状态计算。流量类的主题,采用StarRocks的增量聚合模型出聚合指标。也利用FlinkSQL对于运营分析类业务进行了实时数仓构建,将ADS层结果导入StarRocks供统一接口查询。
整体上也是按照Lambda模型设计的,FLink清洗整合后的合规数据,会通过落盘程序沉降到HDFS,用于持久存储、离线数仓进行跑批及更复杂的模型训练,最终Hive的结果数据也会送到StarRocks供接口查询使用。
数据逻辑设计如右图所示,上面为离线数仓,下面为实时数仓逻辑分层。
可以看到实时清洗后的DWD层数据会成为离线数仓的ODS层,而离线数仓构建好的一些相对固定的维表数据,也会用于实时数仓的流式维度扩展。实时数仓的逻辑分层相较于离线数仓更为简约,DWD明细层会存在于独立的Kafka或者在Flink内存中,DWS层在FlinkSQL聚合完成后就直接下沉到StarRocks了。
这里其实是进行了两次聚合,在Flink里进行了秒级的聚合,而StarRocks里的时间信息相关的维度列是到分钟或者15分钟的,利用StarRocks的聚合模型,将Flink汇聚的5-10s的聚合结果,再次汇聚到分钟级键位。这样设计有两个好处,第一,能够减少LSM模型的Version版本,提升查询性能;第二,抽稀到分钟级后,更便于可视化展示,降低了前端取数的压力。
6.实时即未来,StarRocks后续规划
关于PrimaryKey模型,后续版本即将支持部分列更新,进一步丰富TP业务库还原的能力;并在PrimaryKey模型上支持Bloom Filter、Bitmap等索引能力,进一步提升数据查询性能。
资源隔离方面,后续StarRocks会发布自适应内存、CPU分配能力,客户不再需要手动调整配置参数;未来也会支持多租户资源隔离的Feature。
对于Apache Flink项目的贡献方面,当前Flink-Connector-StarRocks还只具备Sink能力,后续会在Source方面提供支撑,届时用户可以通过Flink分布式读取StarRocks数据,用FlinkSQL做跑批任务。
另外,在CDC适配上,后续也会提供Oracle/PostgreSQL等更丰富的TP库的DDL自动映射能力,适应更多CDC应用。
在云原生时代,StarRocks已经开始了积极探索和实践,很快就会提供存储计算分离、异地容灾等能力,为客户提供弹性、可靠的OLAP层查询分析体验。
以上就是本次分享的全部内容。实时即未来,欢迎大家一起加入到Apache Flink和StarRocks社区建设,共同探索出更多实时数仓的最佳实践。
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。
责任编辑:kj005
文章投诉热线:156 0057 2229 投诉邮箱:29132 36@qq.com





2022年1月9日,StarRocks亮相Flink Forward Asia 2021大会开源解决方案专场,StarRocks解决方案架构...
2022年1月9日,StarRocks亮相Flink Forward Asia 2021大会开源解决方案专场,StarRocks解决方案架构...





