科技
设为书签Ctrl+D将本页面保存为书签,全面了解最新资讯,方便快捷。
2022年3月21日,寒武纪正式发布新款训练加速卡MLU370-X8。MLU370-X8搭载双芯片四芯粒思元370,集成寒武纪MLU-Link™多芯互联技术,主要面向训练任务,在业界应用广泛的YOLOv3、Transformer等训练任务中, 8卡计算系统的并行性能平均达到350W RTX GPU的155%,并已实现商业化部署。

寒武纪训练加速卡MLU370-X8
双芯思元370架构
MLU370-X8智能加速卡提供250W最大训练功耗,可充分发挥AI训练加速中常见的FP32、FP16或BF16计算性能。寒武纪首次将双芯片四芯粒思元370整合在MLU370-X8智能加速卡中,提供了两倍于标准思元370加速卡的内存、编解码资源,同时搭载MLU-Link™多芯互联技术。在YOLOv3、Transformer、BERT和ResNet101训练任务中, 8卡并行平均性能达350W RTX GPU的155%。

MLU370-X8中整合了双芯片四芯粒思元370
MLU-Link™多芯互联技术
MLU370-X8智能加速卡支持MLU-Link™多芯互联技术,提供卡内及卡间互联功能。寒武纪为多卡系统专门设计了MLU-Link桥接卡,可实现4张加速卡为一组的8颗思元370芯片全互联,每张加速卡可获得200GB/s的通讯吞吐性能,带宽为PCIe 4.0 的3.1倍,可高效执行多芯多卡训练和分布式推理任务。

MLU370-X8 MLU-Link 4卡桥接

MLU370-X8 MLU-Link 4卡桥接拓扑
训推一体的Cambricon NeuWare交付优秀训练性能
Cambricon NeuWare支持FP32、FP16混合精度、BF16混合精度和自适应精度训练等多种训练方式并提供灵活高效的训练工具,高性能算子库已完整覆盖视觉、语音、自然语言处理、搜索推荐和自动驾驶等典型深度学习应用,可满足用户对于算子覆盖率以及模型精度的需求。

Cambricon NeuWare为思元370系列芯片提供训推一体加速
在Cambricon NeuWare SDK上实测,在常见的4个深度学习网络模型上,MLU370-X8单卡性能与主流350W RTX GPU相当;而在多卡加速方面,MLU370-X8借助MLU-Link多芯互联技术和Cambricon NeuWare CNCL通讯库的优化,在8卡环境下达到更优的并行加速比。

MLU370-X8 单机8卡部署配置

单卡MLU370-X8性能对比
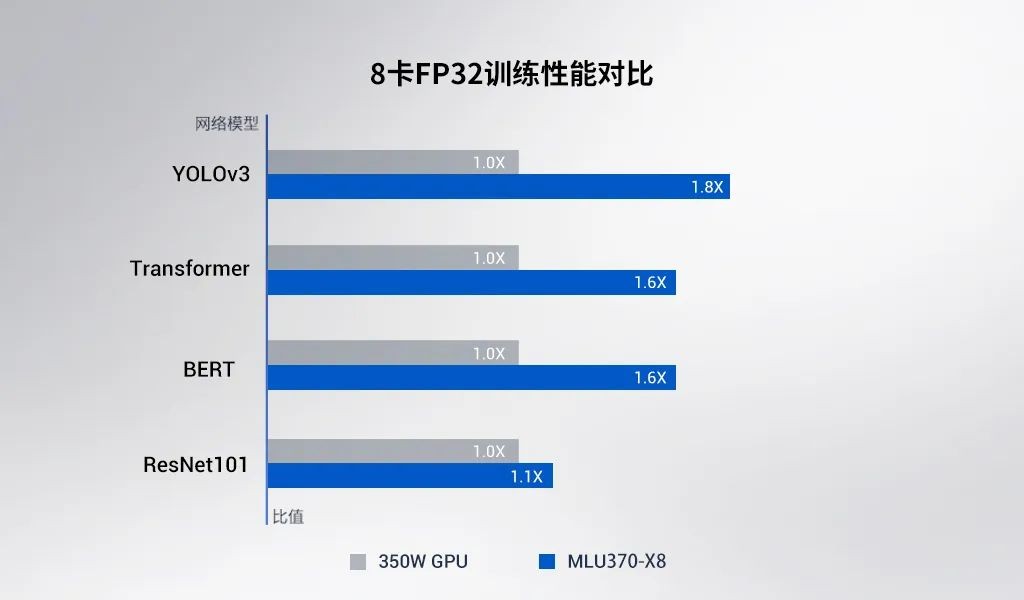
8卡MLU370-X8性能对比
测试环境
250W MLU370-X8:NF5468M5/Intel Xeon Gold 5218 CPU @ 2.30GHz/MLU370 SDK 1.2.0
350W GPU:Supermicro AS-4124GS-TNR/Intel Xeon Gold 6130 CPU @ 2.10GHz/Cuda11.2

MLU370-X8规格表
MLU370-X8补全思元370系列产品线
寒武纪长期秉承“云边端一体、训推一体、软硬件协同”的技术理念。MLU370-X8提供两倍思元370的内存带宽,结合MLUarch03架构和MLU-Link多芯互联技术,将思元370芯片在训练任务的优势充分发挥。MLU370-X8定位中高端,与高端训练产品思元290、玄思1000相互结合,进一步丰富了寒武纪的训练算力交付方式;并与基于思元370芯粒(chiplet)技术构建的MLU370-X4、MLU370-S4智能加速卡协同,形成完整的云端训练、推理产品组合。
MLU370-X8加速卡与国内主流服务器合作伙伴的适配工作已经完成,并已对客户实现小规模出货。
浪潮信息人工智能和高性能产品线副总经理张强表示:“浪潮跟寒武纪目前在思元370系列产品上合作顺利,携手在互联网、金融、制造等领域逐步落地;MLU370-X8的性能优异,我们期待双方可以继续加强合作,为更多的行业和客户带来优秀的人工智能计算力。”
寒武纪用产品向客户印证自己的初心与决心:为人工智能技术的大爆发提供卓越的AI芯片产品,让机器更好地理解和服务人类。
责任编辑:kj005
文章投诉热线:156 0057 2229 投诉邮箱:29132 36@qq.com





2022年3月21日,寒武纪正式发布新款训练加速卡MLU370-X8。MLU370-X8搭载双芯片四芯粒思元370,集成寒武...
2022年3月21日,寒武纪正式发布新款训练加速卡MLU370-X8。MLU370-X8搭载双芯片四芯粒思元370,集成寒武...






