科技
设为书签Ctrl+D将本页面保存为书签,全面了解最新资讯,方便快捷。
近日,昆仑芯科技应邀出席百度技术沙龙第99期“智能芯片”专场:昆仑芯一周年——构筑国产数智基石,AI算力赋能千行百业。四位专家首次同台,揭秘十年磨一剑的中国芯的神秘技术面纱,并系统介绍昆仑芯两代产品赋能千行百业的最新成果及应用实践。
本篇以下内容整理于沙龙第三位演讲嘉宾——昆仑芯科技基础工具链开发负责人张钊题为 “强大易用的昆仑芯软件栈助力生态发展”直播分享。

昆仑芯科技基础工具链开发负责人张钊
我是昆仑芯科技基础工具链开发负责人张钊,今天分享昆仑芯软件栈的相关内容,主要包含以下四个部分:
1)昆仑芯的硬件架构,包括最新一代昆仑芯XPU-R架构以及其中的计算部分和存储部分。
2)昆仑芯的软件栈,包括运行时环境、开发套件、高性能加速库、通信库和图编译加速库。
3)昆仑芯的编程模型,包括编程模型、内存层级和算子开发的方法。
4)昆仑芯和上层框架的合作,主要包括适配的方法和当前支持推理和训练的场景情况。
昆仑芯的硬件架构
第一部分,再次强调我们的新一代昆仑芯XPU-R架构,主要是为了更好地了解软件栈。
昆仑芯XPU-R架构,大体分为计算、存储、互联和接口四个部分。
计算部分主要有SDNN和Cluster。这里面的SDNN就是软件定义的神经网络引擎,是自研核心张量计算单元,加速卷积和矩阵乘法的计算。Cluster主要负责除了卷积和矩阵乘法之外的通用计算部分。
存储部分主要包括GDDR6和Shared Memory,GDDR6是高速内存,提供了512 GB/s的存储带宽,具有较高的能效比和性价比。Shared Memory是片上的共享内存,保证所有计算单元高并发、低延时的访问。
片间互联提供了高速的芯片间互联,有效地支持大规模、分布式的训练,减少通信的延迟。
接口支持PCIe4.0,同时也兼容PCIe3.0,可以灵活适配业界已经上市的一些AI的服务器。
这一代的架构XPU-R是采用SDNN加Cluster的融合架构,既有通用性,也兼顾了高性能。作为第二代架构持续优化,进一步提升了计算性能,同时也增强了灵活的编程能力和通用性。
接下来看一下芯片架构的计算部分。XPU-R主要包含有8个Cluster单元和6个SDNN单元。Cluster单元主要承担通用计算任务,支持SIMD指令,提供通用和灵活的编程能力。SDNN主要承担MAC类计算和EW类计算,提供 128 TFLOPS@ FP16的算力。当然,SDNN也具有灵活的可编程性,能够轻松实现卷积、矩阵乘法、向量计算等功能。
架构中的存储部分,重点看片上高速存储和外存GDDR6。L3 SRAM作为片上高速共享存储,容量为64MB,能够被Cluster和SDNN共享访问。它能够提供比片外GDDR6更低的延时和更高的带宽。在我们软件编程过程中,用好L3 SRAM是提高性能非常重要的手段之一。GDDR6不同的产品形态有不同的容量,比如16GB版本、32GB版本,能够被Cluster和SDNN共享访问。GDDR6作为主要的存储单元,与L3 SRAM的管理基本一致。
昆仑芯的软件栈
接下来进入核心的第二部分——昆仑芯的软件栈。下图是昆仑芯软件栈架构图。

在应用层,我们支持深度学习模型的训练和推理,也支持视频智能分析以及一些科学计算。
在框架层,我们深度适配PaddlePaddle(百度飞桨),同时也支持常见的开源框架,如PyTorch、TensorFlow、ONNX等。
中间部分是昆仑芯的SDK——从下到上包括昆仑芯的驱动、虚拟化模块,还有昆仑芯的运行时库,再往上是昆仑芯的一个以编译器为核心的开发者套件、图编译引擎、高性能算子库和高性能通信库的部分。
之下的硬件部分是昆仑芯AI加速卡。
部署环境方面,支持公有云、计算中心和边缘设备等。
接下来围绕SDK中的各个模块展开,分别介绍各个模块的功能和作用。
昆仑芯的运行时环境这个模块主要包括昆仑芯AI芯片的底层驱动,这是一个内核态的程序;也提供了方便易用的Runtime API,这个是用户态的程序;同时昆仑芯运行时环境包含了大量的管理工具,包括监控、测试、debugger和profiler,这样能更好提升昆仑芯板卡的可操控性,也为上层提供灵活的应用接口。昆仑芯运行时环境主要的特性包括支持多stream、支持SR-IOV虚拟化,也支持event的同步。昆仑芯的运行时环境支持多个平台,如常见的x86-64平台、Arm64平台,也适配国产主流平台。
昆仑芯的模拟器实现了对昆仑芯AI芯片的完全模拟,使用上是由上层的昆仑芯运行时根据上层的配置进行AI加速卡和模拟器之间的控制切换,主要包括了对计算和存储单元的模拟、昆仑芯芯片运行时环境的完全模拟。同时,昆仑芯的模拟器可以提供丰富的工具,包括debugger、profiler和测试工具,既实现了功能级模拟,做到了比特级的精确对齐,也提供了相应的性能模拟,做到计算模块的性能cycle级对齐的水准。同时它支持多个应用场景,包括一些软件栈的功能验证、Kernel的开发和调试,以及Kernel性能的评估和优化。同时,昆仑芯模拟器可以做到和芯片无缝切换。
昆仑芯开发套件是以编译器为核心的一组开发套件,作为昆仑芯的基础工具链,它是基于LLVM开发的,实现了定制化的Clang前端并适配了昆仑芯XPU后端。它是一套完整的工具链,包括编译器、汇编器、linker、compiler-rt(libs)和一些常用的编程工具;同时它支持AOT编译和JIT的方式编译,支持device和host文件的分割和混合编译,向开发者提供一些debugger和profiler工具。
昆仑芯深度神经网络高性能加速库,专门为深度学习设计,是一套高效灵活的软件库,易于集成到机器学习框架中。我们目前集成的框架包括百度飞桨、TensorFlow,还有PyTorch等框架。这套加速库提供了基于Context的一套API,支持多线程和多stream的应用。同时它也支持DNN的一些常用算子,例如矩阵乘法、卷积前向和卷积反向、池化前向和池化反向、激活前向和激活反向等。
昆仑芯通信库,提供了芯片之间的数据传输能力,实现了broadcast、reduce等一系列的通信接口。主要特性包括数据压缩、拓扑检测、多机多卡、跨代兼容的支持,还有异常检测和恢复等。
昆仑芯的图编译加速库是根据昆仑芯硬件相关的设计,做图层的分析和优化,它是基于TVM进行开发的,提供了大量的C++和Python的接口,方便易用。作为一个昆仑芯的推理引擎,可以对接主流的Deep Learning框架导出的模型,也可以直接导入百度飞桨模型、TensorFlow模型、PyTorch模型等。提供了一套编译优化器和运行时分离的工作流程。如下图可以看到一个AI的模型如何进入我们这套图编译加速库,最终进行上线部署的一套过程。

昆仑芯的编程模型
讲完了软件栈的各个模块,接下来第三部分主要介绍昆仑芯XPU的编程模型。昆仑芯XPU编程模型是在典型的异构计算场景中的一个多核并行计算的模型。其中有几个概念。Kernel是描述昆仑芯XPU上的一个计算程序,比较常见;host端是通过设置Kernel函数的执行参数,并发送给昆仑芯device端进行执行。其中一种最简单的CPU和XPU混合编程的流程,可以从这个图中看出,主机端也就是host端执行一段串行的程序,然后通过调用内核函数让设备端并行执行这些程序,如此交错进行。CPU端和昆仑芯XPU端的内存是相互独立的,因此在运行内核函数之前,主机端需要调用内存拷贝的函数,将数据通过PCIe拷贝到设备端内核,运行结束之后,需要通过CPU再次调用内存拷贝函数,将数据拷回到主机端。这是比较常见的一个编程方式。
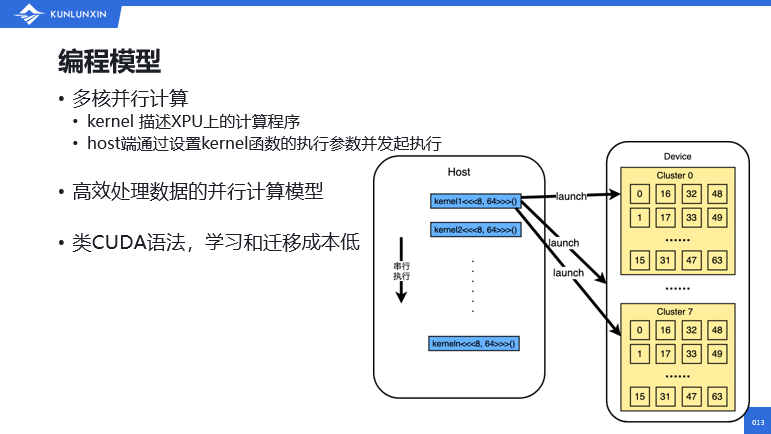
同时我们也支持event和stream的一些工作方式,让CPU和昆仑芯XPU并行工作起来,提升整体的效率。我们这套编程模型可以高效地处理数据。我们采用的是一种类似于CUDA的编程语法,对开发者来说相对友好一些,学习和迁移的成本更低。
为了更好了解昆仑芯XPU的编程和开发,我们必须要掌握其中两个硬件的相关设计和架构。其中第一个是我们的Cluster的架构,这个Cluster向外提供灵活的可编程能力。如图所示,每个Cluster有64个core,每个core内部有8KB的Local Memory,每个Cluster共享256KB的Shared Memory,支持SIMD指令,当然也支持一些特殊的指令,例如内存搬运、同步和原子操作等。

另外一个需要我们掌握是内存层级,了解内存层级才能进行有效的昆仑芯XPU编程开发。从这个图中可以看到,从内部到外部主要分为Local Memory、Shared Memory、L3 SRAM和Global Memory,依次向外分布,越靠内性能越高。我们可以简单地解释为,从L0到L1、L2、L3、L4这些层级相应的一些映射关系,如下表所示。

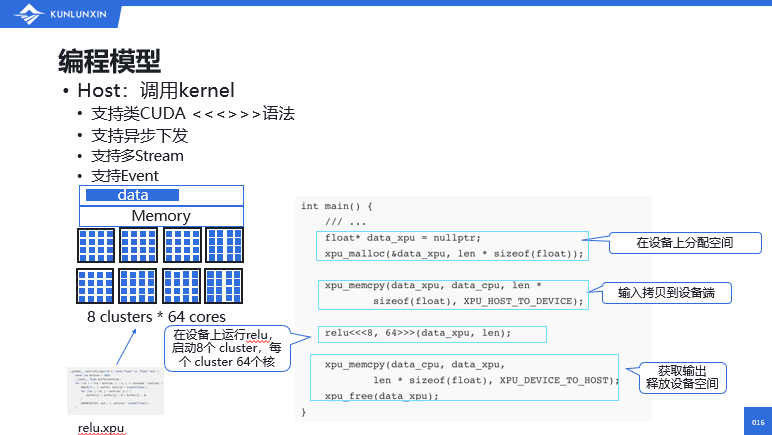
接下来讲一下如何在昆仑芯XPU上开发一段程序。主要分为两个部分:第一部分,在host端即CPU端上开发的代码;另一部分,在device端开发的一段Kernel的代码。在host端,实现一个调用Kernel的流程,大体上需要使用类似于CUDA的这种三个尖括号的语法。
举一个简单的例子。比如一个relu的操作,实现的代码大致是这样:
第一步,我们要在设备端——昆仑芯XPU端分配空间,利用昆仑芯的运行时接口,比如xpu_malloc来实现。
第二步,将左图的这种data输入数据拷贝到设备端。
第三步,让我们的Kernel在设备上运行,relu这个Kernel。这里面有几个参数,比如说启动了8个Cluster,然后用到了每个Cluster里面的64个core,这样我们的 Kernel函数就在device端运行起来,也就是我们左下角的这个relu.xpu的一个程序。
最后,在Kernel运行完之后,我们需要主动地去获取输出。拿到输出之后也要释放设备的空间。
在host的代码大体流程是这个样子。
接下来讲一下我们在device端如何开发一个Kernel程序。
我们在device端实现的Kernel代码,支持类似于CUDA的语法,是C++语言的一种扩展。我们提供了core之间的同步机制,也提供了一些专有的NN的指令扩展。还是以我们这个relu文件为例:我们实现了relu.xpu的一个Device Kernel。
首先,将读入的数据进行分块——基于我们的Cluster_id 和core_id计算出相应的tid,根据这个tid把输入的数据进行分块,相应的数据分给不同的core进行计算;
第二步,每个core会把显示的数据搬运到Local Memory上。
接下来,每个core启动计算,这是一个典型的relu的计算。
之后,会把结果显示的写回到Global Memory之上。
这就是我们一段完整的昆仑芯XPU的Device Kernel的程序。可以看得出来,它和普通的C++的程序比较相似。
昆仑芯和上层框架的合作
讲完了昆仑芯软件栈的功能模块,也讲了如何开发一段算子,接下来讲一下昆仑芯和上层框架的一些合作。
昆仑芯AI加速卡支持各种不同的开源框架,比如PyTorch 、TensorFlow等。这里我们重点讲一下昆仑芯和百度飞桨的合作。
2018年,启动昆仑芯AI芯片和飞桨的合作,从飞桨的1.2版本开启合作;
2019年之后,昆仑芯的代码进入了PaddlePaddle的社区,当时主要集中在Paddle Lite,也就是推理部分;
2020年,昆仑芯和百度飞桨进行了一个小流量的上线。在2020年12月份发布的飞桨2.0版本完全支持昆仑芯的训练。
2021年1月,我们共同实现了实时在线推理服务、超大规模部署。
2022年5月,飞桨2.3发布并全面支持昆仑芯2代的产品。
昆仑芯和飞桨的深度合作形成了一个全栈式的AI技术生态。昆仑芯和百度飞桨是以PaddleCV、PaddleNLP这些产品向外提供知识和服务的,已经完成了主流模型的适配性能优化和精度对齐。
百度飞桨和昆仑芯的适配主要围绕PaddlePaddle框架完成,我们共同完成了框架层面的适配,支持XPU Device和大部分算子,同时也支持分布式训练。昆仑芯的软件栈已经完全集成到了PaddlePaddle的框架里面,完成了适当的对接和支持工作,最终我们可以在一些国产CPU和OS上共同完成生态建设。

重点讲一下昆仑芯和飞桨在推理和训练部分的适配方式。
先看一下Paddle Lite和XPU的推理部分,我们在三个层面上进行了适配:接口层、计算图层、算子层。
接口层,基本实现修改三行代码即可切换到昆仑芯的后端,实现了昆仑芯+CPU自动混合推理。
计算图层,实现了通用图优化,也做了基于XPU的一些图优化,例如融合、缓存优化和权重预处理优化等。
算子层面,我们做了深度学习算子优化、自动代码生成。(上图右)可以看到,通过我们的高性能算子库和paddle进行对接,也可以通过我们的图优化的引擎和paddle进行对接。(昆仑芯支持的一些具体的模型列表可以参见百度飞桨官网。)
昆仑芯与飞桨合作的训练部分主要是昆仑芯XPU和PaddlePaddle框架的适配。这个我们基本上做到了只切换一行代码便可指定到昆仑芯XPU的后端,低成本地从GPU切换到昆仑芯,满足绝大部分用户的需求。同时,支持分布式训练。(具体的昆仑芯训练支持的模型介绍可以参见百度飞桨的官网。)

接下来讲一下昆仑芯和飞桨现在的生态建设。
从上图表中可以看出,从底层的AI算力组件到AI服务器,到国产的操作系统,再到昆仑芯SDK之上,是端到端的AI开发平台解决方案等。这是我们完成的一套端到端的国产AI计算系统的解决方案。昆仑芯原生支持百度飞桨框架、百度的机器学习BML平台,并且训练与飞桨社区进行协同生态建设,已经开源,在国内处于第一份额。昆仑芯加百度飞桨是百度人工智能生态端到端软硬件一体解决方案的独特产品组合,实现了国产AI计算生态的解决方案。
案例分享
分享一个昆仑芯与飞桨合作在工业质检方向的一个具体案例。客户主要做手机上微小零件的质量检测,一开始采用的是用人工检测的办法——用肉眼来检查零部件缺陷。但目视检测不仅速度非常慢,新老员工的检测标准也非常不一致。中期,客户升级到了PyTorch + GPU的方案,成本高且并非国产化方案。后期,通过百度飞桨和昆仑芯的合作和支持,完成了全部切换成百度飞桨加昆仑芯的方案。这是中国自研AI芯片在工业领域首次大规模应用,实现成本降低65%、性能提升9%的效果。
总结
昆仑芯XPU诞生于AI场景,能够满足多样的AI模型和场景需求,提供了较高的性能和能耗效率,给开发者提供了一个相对灵活、易用的编程模型。我们有大规模部署,超过两万片的落地,在技术上能达到100%自主研发,已与多款通用处理器、操作系统和AI框架完成端到端的适配。灵活易用方面,昆仑芯的SDK为开发者提供了全方位的软件工具包,使开发者在转换已有模型、开发新模型以及定义和使用定制化模型时,能够最大化地提高开发效率。
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。
责任编辑:kj005
文章投诉热线:156 0057 2229 投诉邮箱:29132 36@qq.com