科技
设为书签Ctrl+D将本页面保存为书签,全面了解最新资讯,方便快捷。
为解决对冲基金业务中的流计算难题,应对每日海量数据的存储、计算和查询需求,睿凝资本经过对多家数据库选型调研,最终选择了 DolphinDB。本文将讲述睿凝资本使用 DolphinDB 的具体实践。
最初了解到 DolphinDB 是知乎的一条测评贴。作为 KDB+的多年老用户,我对于这家对标 KDB+、测评结果优秀的国产时序数据库非常感兴趣。读帖不久,前公司恰好邀请了 DolphinDB 的创始人周小华博士来做路演,这让我对 DolphinDB 有了更深的认识。告别前公司,结合多年的量化投资经验与数理专业特长,我与合伙人共同创办了北京睿凝私募基金管理有限公司。

睿凝的业务需求
睿凝是一家专注于通过数理建模及程序化交易进行量化投资的对冲基金公司,主要从事对冲基金的多样性策略交易,研发投资策略,为客户提供差异化收益风险特征的资管产品。
在研究策略的过程中,我们每天都要面对大量的交易数据与报价数据,需要处理每日20GB左右的新增数据以及几十TB的历史数据。这是非常大的数据量,对系统的性能要求也非常高。基于对性能和成本的考量,我们尝试搭建一套系统,希望满足以下需求:
查询:分区灵活方便,实现毫秒级响应
写入:系统高吞吐、低延时,实现毫秒级批量写入
计算:计算引擎强大,实现毫秒级实时计算
成本:尽量降低开发与运维的成本
为什么选择 DolphinDB
针对业务需求,我们参考 DB-Engines 的排名将 InfluxDB、KDB+和 DolphinDB 列入选型名单,并且从数据的批量写入、查询和实时计算等方面进行测试对比。根据实际结果来看,DolphinDB 作为当时国内排名第1、世界排名第12(目前排名第9)的时序数据库,性能远远超过其他几家排名更高的数据库。
除了在批量写入、查询和实时计算等方面的性能卓越外,DolphinDB 已经超越了传统数据库简单的存储和查询功能,内置众多量化金融常用的数据分析函数,可以充分满足我们编程建模的需求。
在学习成本方面,DolphinDB 支持类标准 SQL 的语法,脚本语言类似 Python。相比学习 KDB+晦涩的脚本语言,我们的技术人员尤其是新人可以更快上手 DolphinDB,这大大节省了技术人员的培训成本和使用成本。
在流计算方面,DolphinDB 自带优秀的流数据引擎,非常有利于研发的策略在生产环境落地。
在技术服务方面,DolphinDB 具有国内专业的技术支持团队,可以及时解答我们的问题,也会配合我们的需求开发新功能。综合考虑后,我们选择了性能强悍的国产数据库 DolphinDB。
我们用 DolphinDB 做了什么
我们借助 DolphinDB 内置的流数据计算引擎,实时收集行情数据包括逐笔的股票交易和委托数据以及快照数据,然后进行数据的清洗、统计、计算和入库。在使用 DolphinDB 计算我们因子库指标的诸多应用之中,让我以资金流指标和 K 线衍生的价量指标为例,用下面的流程图来说明一下部署 DolphinDB 的流数据计算引擎的技术过程。
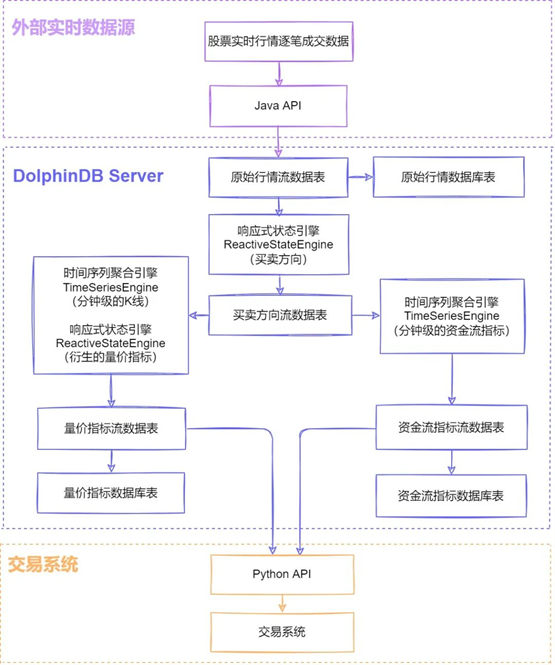
计算资金流指标
订阅买卖方向流数据表,使用时间序列聚合引擎分别计算不同时间窗口的自定义资金流指标。生成资金流指标流数据表。
计算K线衍生的量价指标
订阅买卖方向流数据表,使用时间序列聚合引擎分别计算不同时间窗口的 K 线,与响应式状态引擎级联构成多引擎流水线,使用增量计算的方式高效计算回报率等衍生的量价指标,生成量价指标流数据表。
进行交易与回测
一方面,将计算后输出的流数据表中的数据,通过 Python API 订阅方式推送至实盘交易系统;另一方面,上述所有流数据表通过本地或远程订阅方式写入数据库表,便于后续通过历史数据回放方式进行策略验证与优化。从近半年生产环境运维状况来看,通过 DolphinDB 流数据引擎计算因子可以实现毫秒级响应,整体性能稳定,延时低、吞吐高。
总 结
在这一年多的合作中,不管是性能还是技术服务,我对 DolphinDB 都非常满意。DolphinDB 为睿凝的业务带来了很高的价值。作为多年的 KDB+老用户,我觉得 DolphinDB 的性能已经超越 KDB+、并且还在不断前进中。另外,在接触到的众多软件提供商中并不是所有企业都能真正做到倾听客户,但是 DolphinDB 确实做到了。我很喜欢与 DolphinDB 之间互相倾听与反馈的过程。不管是新的需求,还是 corner case 上的一个小 bug,DolphinDB 都会在第一时间回应,并且很快提供解决方案。
九万里风鹏正举,希望 DolphinDB 越做越好,成为未来量化金融行业的标配!
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。
责任编辑:kj005
文章投诉热线:156 0057 2229 投诉邮箱:29132 36@qq.com











