科技
设为书签Ctrl+D将本页面保存为书签,全面了解最新资讯,方便快捷。
伴随着高阶辅助驾驶加速“进城”,AI大模型开始越来越得到头部自动驾驶企业的重视。
作为当前高阶辅助驾驶研发及落地速度最快的自动驾驶企业,特斯拉最早引入了对Transformer大模型的应用,帮助其不断完善基于纯视觉路线的FSD。
在2020年,毫末智行也几乎同时关注到了Transformer大模型在自动驾驶技术当中的应用潜力,随后逐步在包括多模态感知数据融合、认知模型训练等项目中得到了大规模运用。
近期,我们也会注意到原本以城市NGP为代表、走“重地图”路线的小鹏汽车,不仅要像特斯拉FSD、毫末城市NOH那样走向“重感知”路线,还要加大对Transformer为代表的大模型的运用。
值得一提的是,以特斯拉、毫末智行、小鹏汽车为代表的头部自动驾驶企业,在近几年的技术发展路线上已经越发开始趋同,先是自研终端算力平台、建立云端超算中心,然后在确立“重感知”路线的基础上,提出用大数据驱动大模型、实现自动驾驶加速迭代的目标。
对于这一趋势,在第六届HAOMO AI DAY上,毫末智行CEO顾维灏以《自动驾驶3.0时代》为主题进行了解释。顾维灏认为,在软、硬件能力得到加强后,数据将成为驱动自动驾驶在下一阶段飞速发展的核心。

具体来看,想要实现数据驱动自动驾驶迭代,就要在数据量突破1亿公里后,掌握高效率&低成本进行数据处理的能力,而这也就意味着,自动驾驶企业需要建立起“大模型+大数据+大算力”的组合,由此建立起一套数据闭环体系。
在这之中,大模型的应用已经提上日程,大数据的规模正在加速增长,大算力作为配套也在完善,所以如何基于大模型的要求将数据和算力进行有效使用,就成为了构建数据闭环、实现向自动驾驶质变的关键。
大模型究竟为何被头部自动驾驶企业如此重视,对大模型又将加速自动驾驶的迭代?以上这些问题,我们不妨看看毫末智行是如何解答的。
强感知:大模型带来的并行计算与时序预测
在自动驾驶进入城市场景后,感知系统的压力得到骤增——不同于高速域封闭、简单的场景与变量,城市域中存在着太多难以预料的复杂变量与参与者,而这些都需要自动驾驶感知。
哪怕是驾驶经验丰富的人类司机,面对复杂多变的城市场景,也无法保证能够100%不出事故,包括对方全责;而自动驾驶则必须担起人们对其的全部期待,即眼观六路、耳听八方,由此保证绝对不出事故。
自然,这需要自动驾驶具备更高效、更精准的感知能力,通过建立更真实的感知世界,实现基于感知数据的实时规控策略输出。
高效、精准、真实、实时...如果要实现这些能力,就必须有并行处理海量数据的能力,并且是多维的,而这种能力显然也是传统的算法小模型不具备的。
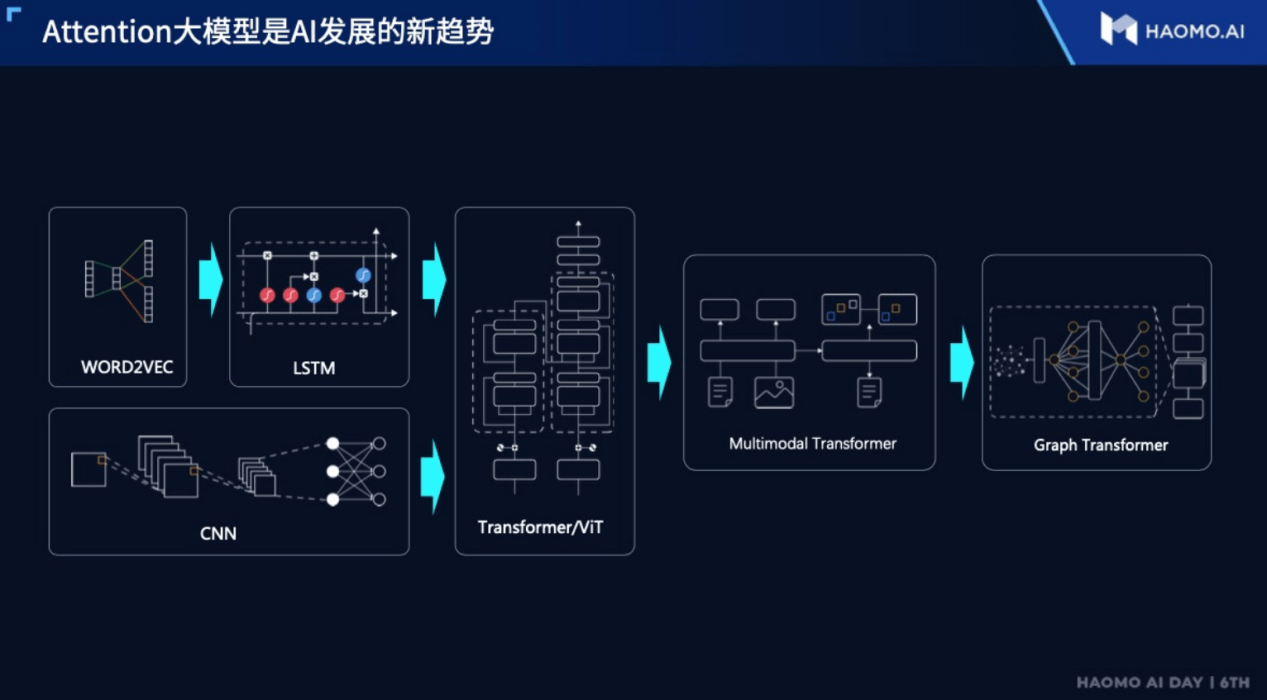
既然小模型无力支撑,那就换更大的。事实上,大模型因其巨大的参数规模和泛化效果,可以为感知系统提供更高的数据处理效率;经过研究者的对比选择,基于Attention机制的Transformer模型就非常受自动驾驶企业的青睐。
Transformer是众多算法大模型中的一种,最初是用于处理NLP自然语言处理的模型,其第一项优势,就是具备并行计算的能力,简单来说就是在算力足够的情况下,处理数据越多,处理效率越高。
这对于如今自动驾驶产品动辄30多个摄像头和雷达的融合感知系统来说简直就是福音,因为由感知系统获取的数据不仅体量庞大,本身还是多模态的——也就是说,大模型不仅要负责让大数据跑起来,还得让它们保持同步,不然摄像头看到有障碍物的地方,激光雷达却没反应过来,这就会让之后负责输出规控策略的模型犯迷糊,带来不必要的麻烦。
这类问题,以往经常出现在使用后融合算法的感知模型上,因为先对各模态数据进行单独融合,更能让数据处理能力有限的小模型接受,相当于每一种传感器,都要配一个独立的感知模型,等到大家输出结果后,再交给一个主处理器进行数据融合。
到了大模型这里,感知系统终于不用受小模型数据处理能力不足的委屈了,通过对多模态感知数据进行并行处理,毫末智行就只用一个感知模型,输出一套包含全部信息的结果,这在业内被称作前融合算法。
除了并行计算能力,Transformer这种具备Attention机制的大模型对时序特征还有着天然的关联优势。举一个简单的例子就是,感知系统要如何将结果映射到BEV网络上,成为一个连续、可预测的感知世界?

Transformer可以做到这种效果。不仅如此,通过毫末智行的各种实践,我们还能发现它的更多作用,比如将多视角的摄像头图像进行融合,输出更真实、精确的画面;并且在此基础上,实现诸如红绿灯绑路、车道线识别等功能。即使这些信息遭到遮挡、中断,Transformer也能借助时序预测能力,将它们正确地“脑补”出来。
认知强化:化解长尾难题,让判断更“拟人”
完全模拟,并替代人类驾驶,是人们对自动驾驶的终极目标,但考虑到当下的公共交通都是建立基于交通规则和人类司机灵活处置的基础上的,所以自动驾驶也必须要足够拟人化,才能在适应交通环境的要求,满足人们对自动驾驶安全的期待。
在大模型得到大规模应用前,自动驾驶实际已经能够依靠较为成熟的认知小模型,实现一些应对复杂城市场景的规控策略输出了。但就和在感知部分提到的一样,由于小模型的带宽有限,导致其无法处理连续多种场景的数据集,并且在面对单个数据集太过庞大的场景时,可能也很难做到高效的处理。
这就会带来两种可能,一种是自动驾驶无法高效处理如无保护左转这种变量多且复杂的单一场景,另一种是无法统一连续多场景的规控策略,不仅会给驾驶者和乘客带来生硬、不连贯的驾乘体验,还会拖累其它交通参与者的通行效率。

这一难题在大模型投入大规模应用后将可能得到有效解决。基于并行计算能力,大模型首先能够轻松化解数据集庞大的各类复杂场景;而在此基础上,自动驾驶也可以使用经过筛选的标注数据对大模型进行预训练,使其能够输出一套基于统一认知体系的小模型,如此又能实现模型间更高效的协同能力,输出的规控策略也能在此基础上更拟人化。
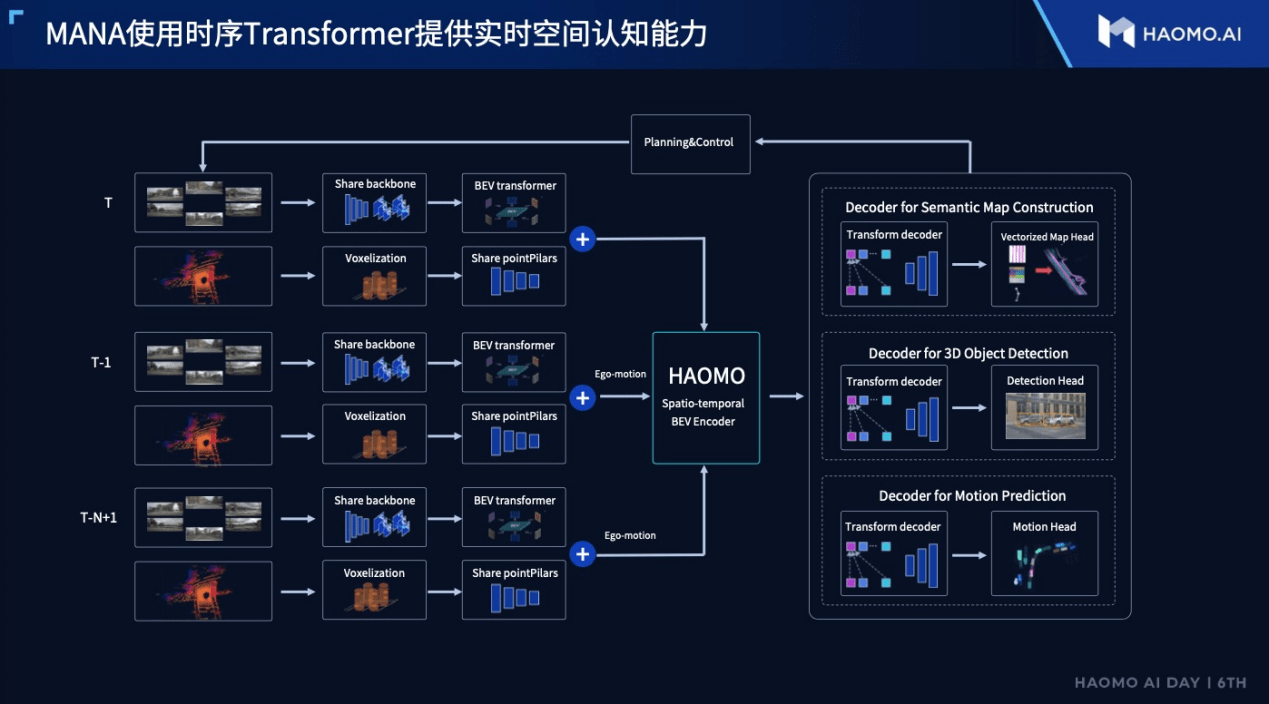
毫末智行就是这样使用的Transformer大模型的。首先是使用标注过的高质量数据对大模型进行预训练,使得自动驾驶决策更像人类实际驾驶行为,以保证实现自动驾驶决策的可控、可解释,而在这之后也可以用其训练其它认知模型,形成类似CPU芯片大核+小核形式的大模型+小模型组合,实现对各类场景数据更灵活、高效的应对。
标注升级:为大数据做“预习”,提升效率
标注工作虽然看似简单,对于自动驾驶来说却十分重要——由于人类语言与计算机语言是不相通的,所以标注就在一定程度上,充当起了自动驾驶的人类世界翻译官。
另一方面,既然要靠数据驱动自动驾驶迭代,那么在海量数据中,哪些数据是优质的,哪些数据是劣质的,这些数据都有什么样的特征,也都需要通过标注进行筛选。
对于特斯拉、毫末智行、小鹏这类自动驾驶企业而言,想要提升标注效率最直接有效的办法,就是引入并不断提升自动标注能力,而人工标注也会参与其中,进行辅助。
但这种自动+人工组合所能提供的效率提升是有限的,当数据量突破1亿公里后,海量的待标注数据将直接捅穿现有标注能力的天花板,严重影响到自动驾驶的迭代速度,但如果用“笨办法”无脑叠加标注资源的规模,又会带来更高的成本。
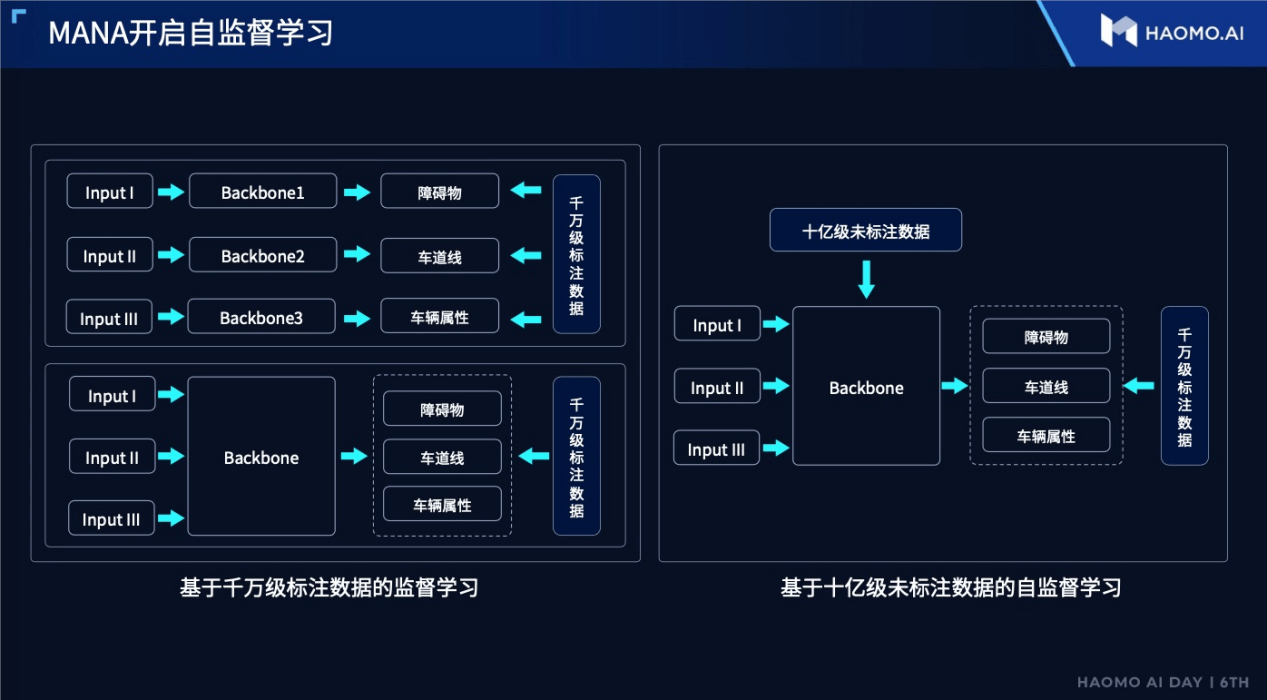
考虑到这一情况,毫末智行提出了一种新设想,就是借助大模型,建立无标注的自监督学习。其逻辑有点类似于我们在学生时代的“预习”,先对课本章节和内容有一个大致的了解,然后到正式学习到任意一章时,就可以快速进入状态。
而无标注自监督学习的逻辑则是,先统一所有感知任务的backbone,再使用以无标注数据为主的数据,对大模型进行预训练,使大模型获得能够使用无标注数据训练的能力。这里同样使用了大模型并行计算的能力。
验证升级:发挥大算力优势,让仿真系统更真实
最近“元宇宙”的概念很火,而对于自动驾驶来说,它的“元宇宙”就是仿真系统。所有经过了大模型预训练的算法模型都将在这里进行验证,相比在真实场景下验证,通过仿真系统验证不仅更安全,效率也更高。
但就像玩电脑游戏一样,哪怕是设计再精良的3A大作,很多时候我们也会吐槽其真实性,比如高速行驶中的汽车,只要一按空格就能实现原地刹停;静止摆在马路中央的塑料桩桶,汽车撞上去后也没有太大影响等等。
如果想要保证落地后的自动驾驶真正具备安全、舒适、高效等特性,那么作为主要的验证和训练场所,仿真系统就必须保证绝对真实;但越是真实的仿真系统,就越需要更多的真实场景数据信息加入,这又会增加仿真系统算法模型的压力。

为了解决这一难题,特斯拉、毫末智行、小鹏等自动驾驶企业都做出了相同的部署,即想方设法为仿真系统引入更多真实世界的数据,使其能够100%还原真实世界,并能够模拟出各种场景。
在这里,毫末智行同样采用了大模型这一撒手锏,并且在组成大算力+大模型的同时,通过与阿里、德清政府的合作,将真实世界中采集的交通流引入到仿真系统中。
大数据的加入不仅让仿真系统能够将大算力与大模型优势真正发挥出来,也进一步提升了仿真世界的真实度,而通过仿真系统验证并训练过的算法模型,自然也就更加成熟了。
算力升级:科学分配算力性能,让训练更高效
仿真系统只是提供模拟场景,训练算法模型才是其核心。通过以上的介绍我们可以明白,只有通过训练,经过大数据洗练的算法模型才能走向成熟,而由长尾导致的认知难题也将在引用高价值数据的训练后被逐步化解,由此逐步实现辅助驾驶向自动驾驶的质变。
但就像人类要通过至少十多年的学习教育才能作为人才输出社会一样,自动驾驶的训练成本也非常高昂,这一点的直接体现就是算力。同样是玩大型游戏,你电脑的CPU和显卡算力越高,游戏运行起来就越流畅,画质也能开到最大。

为了解决这一难题,特斯拉、毫末智行、小鹏等自动驾驶企业都做出了相同的部署。通过建立云端的超算中心,提升算力储备;而在拥有大算力之后,借助大模型的并行计算能力来提升大数据的处理效率也就势在必行了。
不过,即使是像Transformer这样遇强则强的大模型,也需要基于训练效率进行合理分配,因为在突破1亿公里后,自动驾驶的数据集体积也会越发膨胀,即使超算中心应付得了,在加入新的高价值数据后,同时处理一整个数据集,也终究会在占用过多算力资源的基础上,影响正常的训练效率。

在这里,毫末智行又为大模型提供了一项“减压”操作,具体来看就是引入增量式学习的方法,自动驾驶不再以一整个数据集为单位进行训练,而是进行等比例的“科学分配”,即从总数据集中摘取一小部分,与新加入的高价值数据融合,然后在将其训练结果与总数据集进行同步。
这样做的好处是非常明显的,除了为大模型和大算力减压增效,新数据在加入总数据集时,也非常可能会被稀释掉,导致系统无法从中训练出想要的结果。而经过毫末智行这样类似“等比例的转换”方式,就可以有效保证训练结果,让大数据真正体现出价值。
等待数据闭环的“东风”
大模型的引入对提升数据处理能力、构建数据闭环起着举足轻重的作用。而在通过大模型大幅提升算法软件性能的同时,以软件驱动的自动驾驶2.0时代也将由此逐步走向末尾。
当然,作为构成数据闭环中的一部分,在积极引入、并发掘大模型潜能的同时,自动驾驶企业也不能忽视大数据与大算力这两部分。
对于数据而言,特斯拉已经通过全球多座超级工厂的落地,将旗下量产乘用车的设计年产能提升到了百万级,后续仅需影子模式就能坐享海量数据;而毫末智行也依靠乘用车辅助驾驶的量产规模,加速数据的获取速度。
而在算力方面,特斯拉、毫末智行、小鹏汽车均已官宣了其云端超算中心的最新进度,其中特斯拉Dojo最快明年就能实现落地,而毫末智行的超算中心也在紧锣密鼓准备中。
万事俱备,只欠东风,如今唯一需要加以耐心的,就是时间。在大模型、大算力性能稳步推进、优化的同时,只待数据量突破1亿公里后,由大数据+大模型+大算力的数据闭环就将正式搭建完成,这些自动驾驶企业也将就此进入3.0时代,最终真正实现由量产辅助驾驶向完全自动驾驶的质变。
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。
责任编辑:kj005
文章投诉热线:156 0057 2229 投诉邮箱:29132 36@qq.com




Mass General Brigham 是首批在 Nuance 精准成像网络上加速端到端 AI模型开发和临床工作流部署的...
Mass General Brigham 是首批在 Nuance 精准成像网络上加速端到端 AI模型开发和临床工作流部署的...
11月17日,SOPEXA与Daxue Consulting联合举办线上研讨会,并首次在直播中发布了China& 39;s Wine & S...