科技
设为书签Ctrl+D将本页面保存为书签,全面了解最新资讯,方便快捷。
产品技术的演进,离不开底层科技的创新。人工智能已经成为新一轮科技革命和产业变革的重要驱动力量,基于强算法、大算力和大数据的大模型发挥着关键作用。
在9月22日于广州举办的2023年中国企业出海高质量发展创新大会上,琶洲实验室-人工智能与数字经济实验室(广东)(简称琶洲实验室)科学家谭明奎教授以《大模型历史机遇与挑战》为主题发表开场演讲。谭教授认为,企业出海面临诸多挑战,在加速本土化落地、跨境贸易合作、数字内容创意开发等方面,大模型有着强大的技术能力赋能企业。

与此同时,大模型对数据需求量、计算资源等各方面的高要求,单一机构没办法完成,这要求科研单位和企业一起紧密配合,在典型领域实现数据、模型、算法的共享和协同开发,促进大模型研究的应用和部署。
大会现场,钛动科技、琶洲实验室和华南理工大学未来技术学院正式签约“人工智能出海营销战略合作”。

三方将在人工智能出海营销领域展开长期战略合作,打通“数据-算法-应用场景”全链条,深度融合技术与产业,赋能中国出海企业数字化转型,助力更多中国企业走出国门、闪耀全球。
以下为经整理的演讲精华内容。
《大模型历史机遇与挑战》
01 大模型概述
大模型到底是什么?
早在2017年,学界便开始对人工智能大模型进行研发。直到2022年ChatGPT发布,其逻辑性的流畅对话和交互能力给全球带来震撼,才让人工智能技术备受关注。而ChatGPT能够脱颖而出的关键点,就是大语言模型的突破,这给数字经济和人工智能技术发展带来了新一轮的契机。
近几个月,国内国外陆续发布各大模型,又被称为“百模大战”。今年3月份发布的Open AI GPT-4,增加了多模态能力,在文本处理、写代码等多种专业能力上有了质的提升,并且将会随着演进迭代逐步提高大模型的技术能力。那么大模型的上限能力在哪里?我们目前还不知晓。但就目前呈现出来的能力而言,已经足够让我们惊艳,也足够让我们去利用它,来解决数字经济、尤其是出海业务中的难点和痛点。

大模型基于Transformer 架构开展,它是模型的底座,也是处理长序列数据的核心技术能力。而Transformer 结构的发展,离不开海量数据的“投喂”。2018年,谷歌带着3亿参数BERT模型,闯进大众视野,而到目前,ChatGPT-3模型参数已经达到1750亿,参数规模提高到千亿级别。未来,高容量的参数可以让我们将人类历史上所有能够数字化的内容以及每天产生的新数字化内容全部包含进大模型数据中。因此,大模型的记忆能力、联想能力、创作能力,都将优于人类的能力。
同时,技术的提升在大模型应用部署层面,也带来了新的范式。
过去,从需求分析-现场数据采集、标注等步骤到模型训练-部署,整个流程需要耗费几个月时间。
现在,基于大模型能力+部署框架+场景数据,有望实现几个人在数小时之内完成模型部署方案。
02 大模型机遇与展望
从通用大模型转向行业大模型,在出海业务领域,大模型有哪些机遇?

首先是在出海营销洞察层面,本土企业如何获取最地道的目标市场洞察?依托处理和解析海量、高维和多源数据的能力,大模型通过自动在海外收集大量数据,识别隐藏在多维数据中的细分市场、关键词、风险预判等重要信息,解析复杂的消费者行为,帮助决策者足不出户深度洞察海外市场。大模型为广告方案提供数据驱动的决策支持,其洞察能力超过本科生水平。
第二是在营销内容层面,目前大模型在数据生成尤其是图像、文本生成能力让人非常惊艳,有些能力已经超过了硕士、博士甚至是资深教授水平,可以帮助企业快速生成高质量、一流的数字内容。同时还可以将创作人员的优质创作思路用数据的方式呈现,形成标准范式,让内容生成环节上的每位工作者快速获取新思路,避免在协同过程中出现创意思路的偏差,极大地提升创意交付效率。
第三,在服务链路层面,从市场研究、用户画像,到营销内容生成,再到chat客服、售后调研等,大模型可以帮助出海公司在交付前、中、后全链路地进行优化提升。
第四,在智慧办公层面,本土企业如何与海外企业高效协同合作?大模型可与公司办公及会议系统整合,帮助用户在开会期间更高效地处理和记录信息,例如协助用户制定详细会议提纲、会议准备待办事项、根据会议内容生成创意性想法和建议、生成会议纪要总结等,有效提升行政效率。
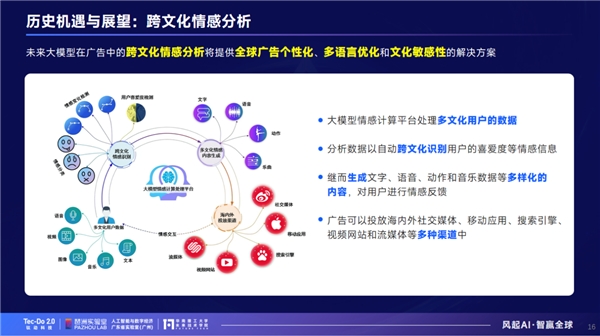
第五,在跨文化情感分析层面,大模型不仅可以解决跨语言沟通,还能实现跨文化沟通。大模型通过收集海外数据信息,形成对当地文化的理解,了解不同文化之间的相似性和差异性,实现快速准确的翻译,帮助人们更好地理解不同文化和语言背景下的思维和表达方式。未来,大模型在广告中的跨文化情感分析将发挥重要作用。通过对全球多文化用户广告点击率、留存率、观看量等信息数据分析,提供全球广告个性化、多语言优化和文化敏感性的解决方案,传统AI模型做不到,只有大模型有这个能力。
03 大模型应用挑战
无论是训练还是应用部署,大模型仍然面临很多挑战,这需要高校、研发机构、企业紧密结合在一起,协作攻克。
首先,大模型面临着使用过程中的人机交互挑战,也是目前大模型应用需要尽快解决的一个痛点。由于大模型自身“大”的特点,ChatGPT-3模型参数已经达到1750亿,GPT-4的参数达到了1.8万亿个(也有报道为5000亿),如此高额的参数容量在调动、运行时对运算要求非常高。当应用到实时或交互性要求较高的场景时,容易出现响应延迟、速度慢等状况,从而影响用户体验。从业者需要对大模型运算架构、模型压缩、加速运算等方面提供更先进的解决方案。
另一方面,大模型到目前为止,还缺乏对人类情感和语义的深入理解,可能导致模型在处理情感相关的交互或场景时出现问题。同时,数据来源可能本身具有偏见和歧视,大模型在学习时可能会从训练数据中学习到潜在的偏见和歧视,并在生成结果时产生不公平或歧视性的偏好。

第二个挑战来源于瞬息万变的现实世界。我们正处于一个信息爆炸的数据时代,面对场景数据动态变化,模型需具备增量学习和持续更新的能力。具体到出海行业而言,出海企业面临着跨文化、跨场景挑战,这要求大模型针对不同国家、不同地区、不同场景进行针对性的学习和部署,包括增量学习、适应学习等,从用户实际应用需求出发,凝练为科学问题加以解决。

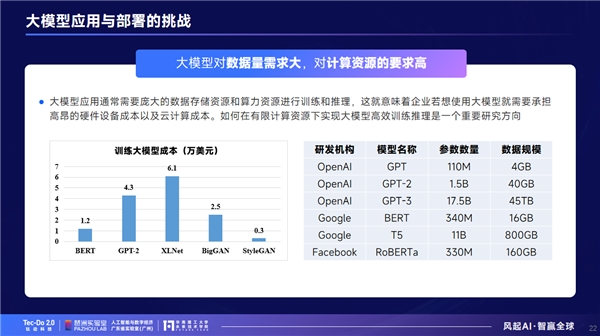
第三个挑战来源于大模型开发的成本要求,大模型对数据需求量大,对计算资源要求高。OpenAI训练1750亿参数的GPT-3费用大概是1200万美元,训练5000亿参数(业界预估)的GPT-4成本飙升至1亿美元,普通科研高校或科研单位没有办法独立负担。
大模型在开发和应用过程中主要受限于以下三方面成本:
• 训练成本。包括算力、电费等
• 数据收集成本。
• 人力成本。支付大模型训练开发人员的高额薪水
这要求科研单位和企业一起紧密配合,结合各自优势,在典型领域实现数据、模型、算法的共享和协同开发,促进大模型研究的应用和部署。
除了以上在开发、应用部署和使用三个环节可能会面临到的挑战之外,大模型可能存在私密数据泄露风险和合规性风险,这也是广泛民众最能感知也最为关注的问题。现在有关部门正在逐步推出相关制度和法律,企业需要紧跟律法脚步,确保开发过程中的合法合规。
琶洲实验室大模型团队围绕数据、模型、算法、应用成立专项小组,目前超过100人,包括教授4名、副教授4名、博士16名、硕士64人、且正在逐步壮大。
本次大会上,琶洲实验室、华南理工大学正式与钛动科技签订三方合作条约,相信通过产学研三方强强联合,深入AI应用的深水区,推动迭代升级,产出有原创性、突破性、对行业发展有重大影响力的高水平研究成果,推动中国商品、中国品牌更好地走向全球。
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。
责任编辑:kj005
文章投诉热线:156 0057 2229 投诉邮箱:29132 36@qq.com











