科技
设为书签Ctrl+D将本页面保存为书签,全面了解最新资讯,方便快捷。
大数据和人工智能技术热度依旧!从概念验证到可持续的商业模式落地,数据价值的输出,仍需要大量的基础工程研究和开发。近期,DATA · AI CON 2023 在上海拉开帷幕,包括 Zilliz 在内的数据库龙头厂商受邀参加,共话行业新趋势。
据悉,本次会议由上海白玉兰开源开放研究院和人工智能开源软件发展联盟联合主办,并获得了 Milvus、Ampere Computing、火山引擎、Cloudera、Apache Software Foundation、LF AI & Data Foundation 等企业和社区的强力支持,旨在共同推动数据与人工智能技术的进步与应用领域的拓展。
本次会议论坛涵盖现代数据架构、数据工程与大模型落地、AI 存储基础设施、生成式 AI、超大规模计算、云原生等主题技术论坛。Zilliz 资深开发者关系布道师李成龙在 【AI 存储基础设施】论坛进行了主题分享。

李成龙在现场分享
李成龙表示,当前对于非结构化数据的处理主要面临四大挑战:
数据体量巨大,未来超过80%的数据属于非结构化数据,AIGC 时代多模态数据的生成速度远远超过结构化数据,系统扩展性性能至关重要
非结构化数据理解困难,虽然 LLM 已经大幅降低了非结构化数据理解的成本,但由于数据质量、多模态,成本性能等问题,单一大模型并不能完全解决
非结构化数据理解的问题,很多场景下依然需要多模型组合,搜索与生成结合等方法
对算力的要求巨大,推理、向量数据库存储检索等都是算力密集型应用。算力的需求和成本往往成为挖掘非结构化数据的一大阻碍。 而处理非结构化的工具却极其短缺,虽然传统的结构化数据处理并不简单,但由于 ETL、数据库、数据仓库等工具在过去30年的发展,已经变得相对成熟。然而,非结构化数据处理的工具链刚刚开始构建,这就使得非结构化数据的处理相比结构化数据更具挑战性。
在此背景下,向量数据库应运而生。向量数据库具有快速计算向量相似度的优势,能在 N 个向量中找出与目标向量在高维空间中最相似的前 K 个向量。目前,向量数据库主要分为四个类别:
基于 PostgreSQL、ClickHouse 等进行魔改或者插件化实现的向量数据库。这类解决方案以现有的关系型数据库或列存数据库作为基础,通过修改或插件扩展的方式添加向量搜索功能,PG Vector是这类解决方案的代表产品。
基于传统倒排搜索添加稠密向量索引支持的向量数据库。这类解决方案以倒排索引搜索引擎作为基础,通过扩展索引机制以支持向量搜索,ElasticSearch是这类解决方案的代表产品。
基于向量检索库实现的轻量级向量数据库。这类解决方案以向量搜索库(如 Faiss)为核心,围绕其构建数据库功能。这些产品通常具有较小的体积和较高的运行效率,Chroma 是这类解决方案的代表产品。
基于原生向量设计的云原生分布式向量数据库。这类解决方案从零开始设计和实现向量数据库,整个系统从底层到顶层都针对向量搜索进行了优化,通常提供了更完整和高级的功能,包括分布式计算、容灾备份、数据持久化等,Zilliz Cloud/Milvus 是这类解决方案的代表产品。
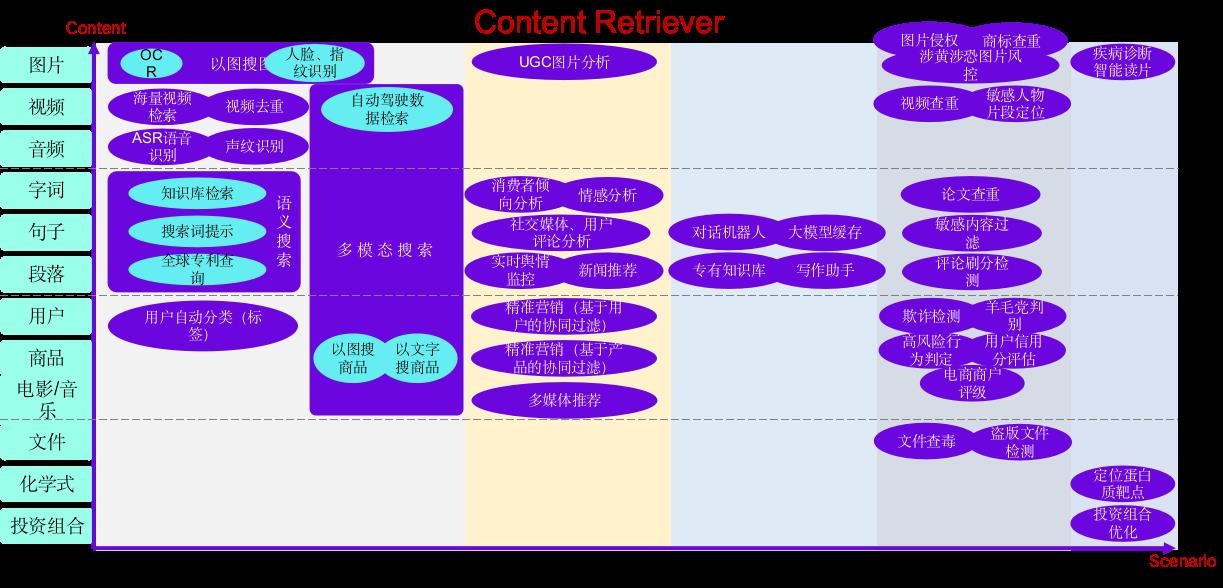
向量数据库适用的业务场景
李成龙强调,Milvus 经历了从 1.0 架构到 2.0 架构的升级,无论在性能、成本、功能还是易用性等方面都处于行业领先位置,被全球超过 1000家 企业用户所信赖,拥有超过 700 万次下载和安装,最大库规模超过20亿条向量。Milvus 是为云而生的向量数据库,具备以下特性:
分布式云原生,基于 K8s 进行微服务化设计;
存储计算分离,弹性扩缩容;
高可用,故障分钟级恢复;
百亿级向量的扩展能力;
基于消息队列实现数据的实时增删;
集成 OpenAI、LangChain、Huggingface、Pytorch 等 AI 生态;
强大的生态工具 - GUI、CLI、监控,备份。
值得一提的是 Zilliz Cloud,它是 Zilliz 公司基于开源向量数据库打造的全托管企业级向量检索服务,分为 SaaS 和 PaaS 两个版本,面向不同需求和不同部署环境。李成龙提到,Zilliz Cloud 基于 Zilliz 自研的向量检索引擎 Cardinal,性能成本相比于开源提升3 倍。此外,Zilliz Cloud 提供大量企业级功能,助力用户聚焦业务逻辑,Zilliz Cloud目前已经登陆 AWS、GCP、Azure 和阿里云,即将登陆金山云。
责任编辑:kj005
文章投诉热线:182 3641 3660 投诉邮箱:7983347 16@qq.com











