科技
设为书签Ctrl+D将本页面保存为书签,全面了解最新资讯,方便快捷。
日前,Meta发布最新开源模型Llama 3并号称是性能最好开源大语言模型,极有可能超过当前的闭源王者GPT-4 Turbo。那么,Llama 3能力究竟如何?
4月24日,由清华大学基础模型研究中心联合中关村实验室研制的SuperBench大模型综合能力评测平台,基于语义、对齐、代码、安全和智能体5项大模型原生评测基准,展开开放性、动态性、科学性和权威性的大模型综合能力评测,率先剖析Llama 3模型能力。
《SuperBench大模型综合能力评测报告》对Llama 3-8B、Llama 3-70B等16个海内外具有代表性的模型进行了评测。结果显示,Llama 3与GPT-4系列模型仍有一定差距,而国内大模型智谱AI的GLM-4与百度文心一言4.0在多项评测中进入榜单前五名,超过Llama 3。
在语义理解能力评测中,国内大模型GLM-4、文心一言4.0分别位列第二名、第三名,仅次于Claude-3,但超过GPT-4网页版与GPT-4 Turbo,稳占第一梯队。Llama 3-70B、Llama 3-8B则分别位列第六名、第十六名。
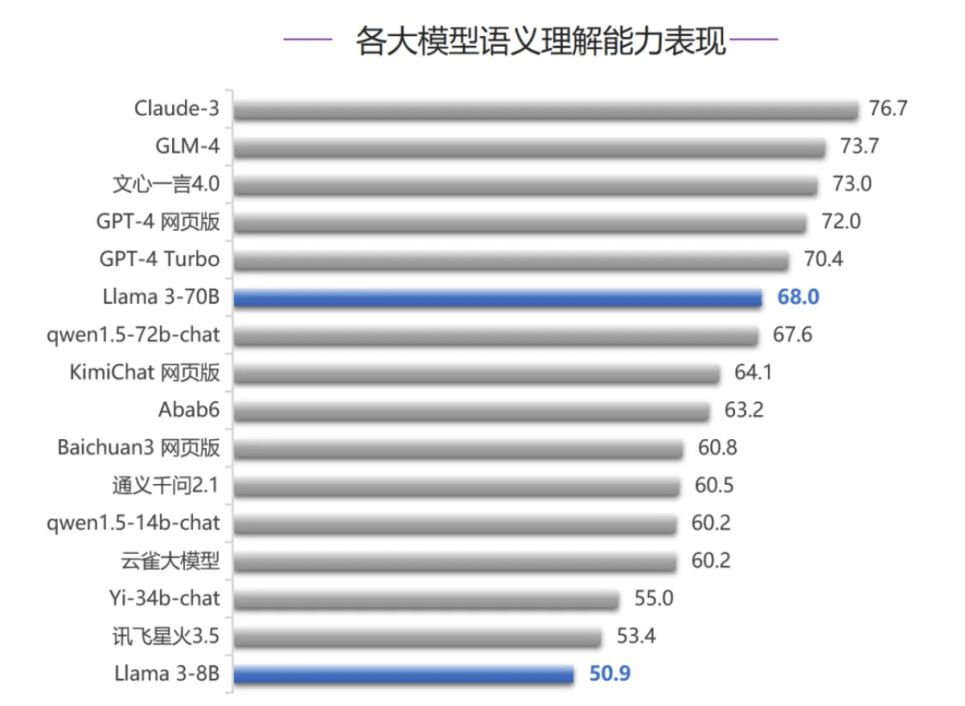
而在智能体能力评测中,Llama 3-70B跻身榜单前五名,这也是该模型五项评测排名最高的一次。在代码编写能力、人类对齐能力、安全和价值观三项评测中,Llama 3-70B均排在第七名,超过大部分国内大模型,只落败于GLM-4和文心一言4.0,Llama 3-8B排名相对靠后,考虑到模型参数量的差异,Llama 3-70B整体表现较好。
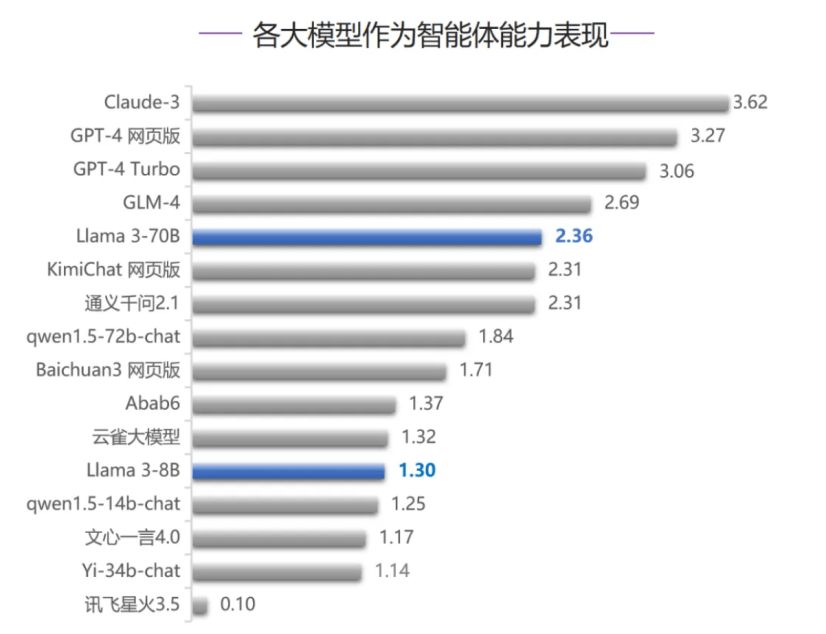
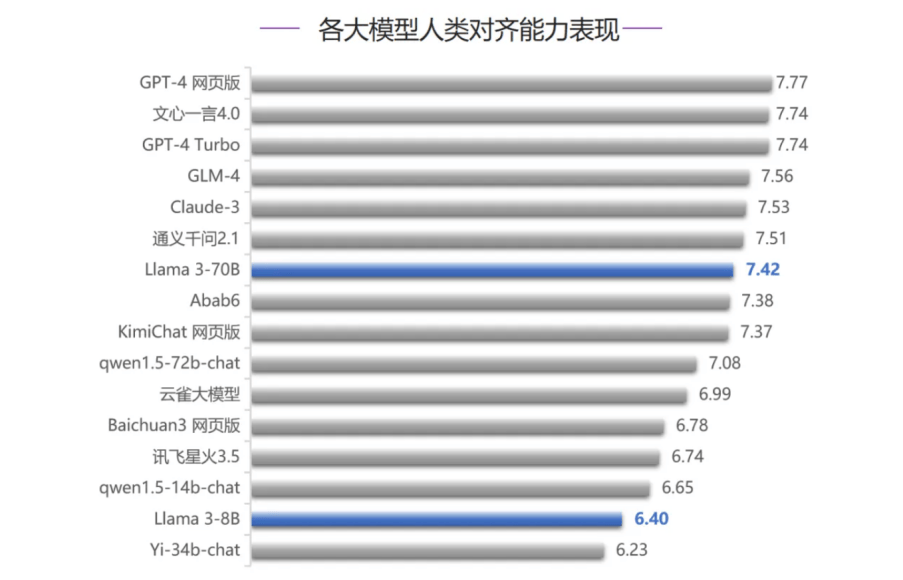
相较之下,表现出色的国内大模型GLM-4全面对标OpenAI,在五项能力评测中均紧追GPT-4系列模型与Claude-3,堪称“全能选手”。同时,在代码、智能体两项大模型关键能力评测中,GLM-4排名仅次于GPT-4系列模型和Claude-3,位列国内第一。

在安全价值观能力评测中,文心一言4.0拿下最高分,超越GPT-4系列模型和Claude-3。在智能体能力评测中,文心一言4.0表现较差。
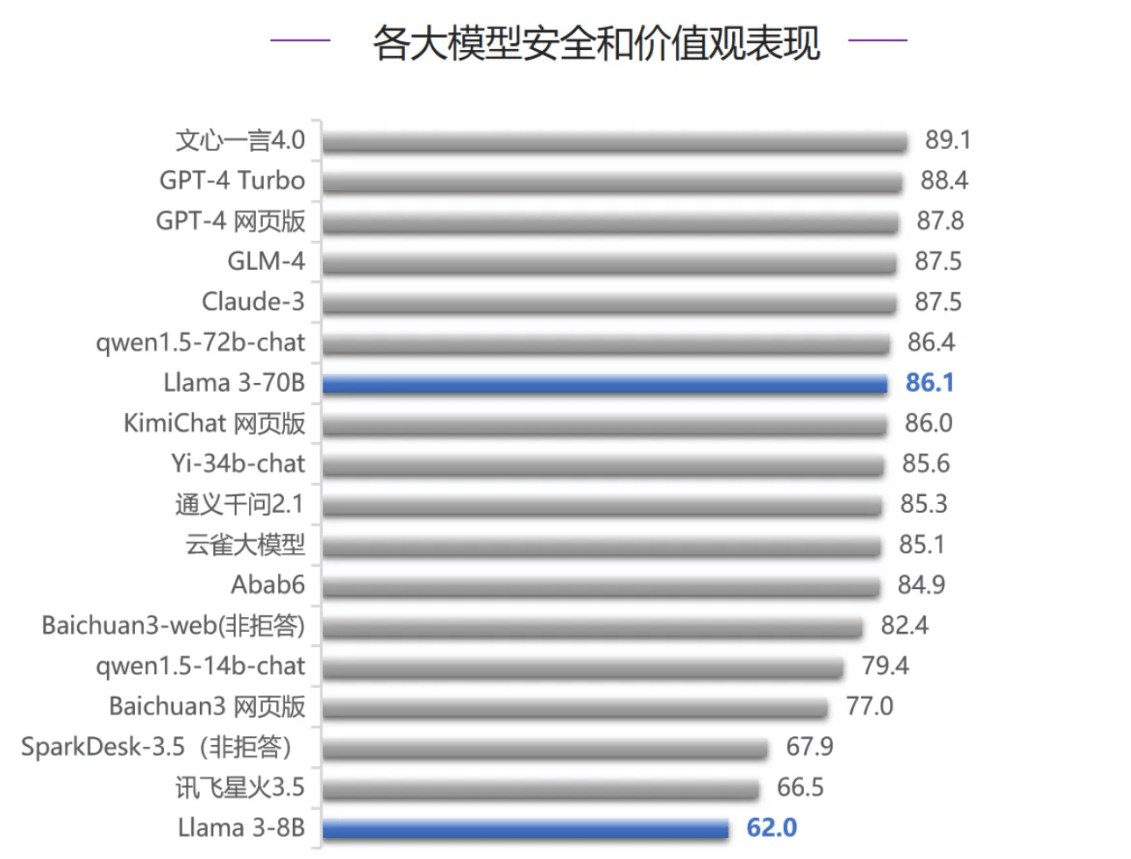
总体而言,虽然国内大模型与国际顶尖模型之间还存在差距,但正逐步缩小这一差距。相信在政策支持和技术创新的推动下,国内大模型将取得显著成就,推动我国人工智能产业高质量发展。
责任编辑:kj005
文章投诉热线:182 3641 3660 投诉邮箱:7983347 16@qq.com



由卧兔网络主办、特邀TikTok Shop参与的百业万品·助无忧出海 TikTok Shop跨境电商2024宁波首场招商...