科技
设为书签Ctrl+D将本页面保存为书签,全面了解最新资讯,方便快捷。
一、行业痛点
众所周知,在选择嵌入式 SoC 处理器时,面积和功耗通常是客户核心考虑的两大因素!常规的嵌入式系统程序大多需要储存在芯片上,如果系统代码密度低就需要更大的内存来承载。而与此同时、成本也相应增加。由此可见,代码密度决定了片上内存的规划容量,对芯片的面积、功耗和整体成本有着深远影响!
相比成熟的 Arm 架构,代码密度并非 RISC-V 传统强项。在 ArmCC 等商业编译器的加持影响下,某些应用场景中两者代码密度差距甚至达一倍之大, 因此,RISC-V 所需的存储器和相应成本也大大增加。
这些因素也正成为困扰客户、影响行业发展的一大难题!
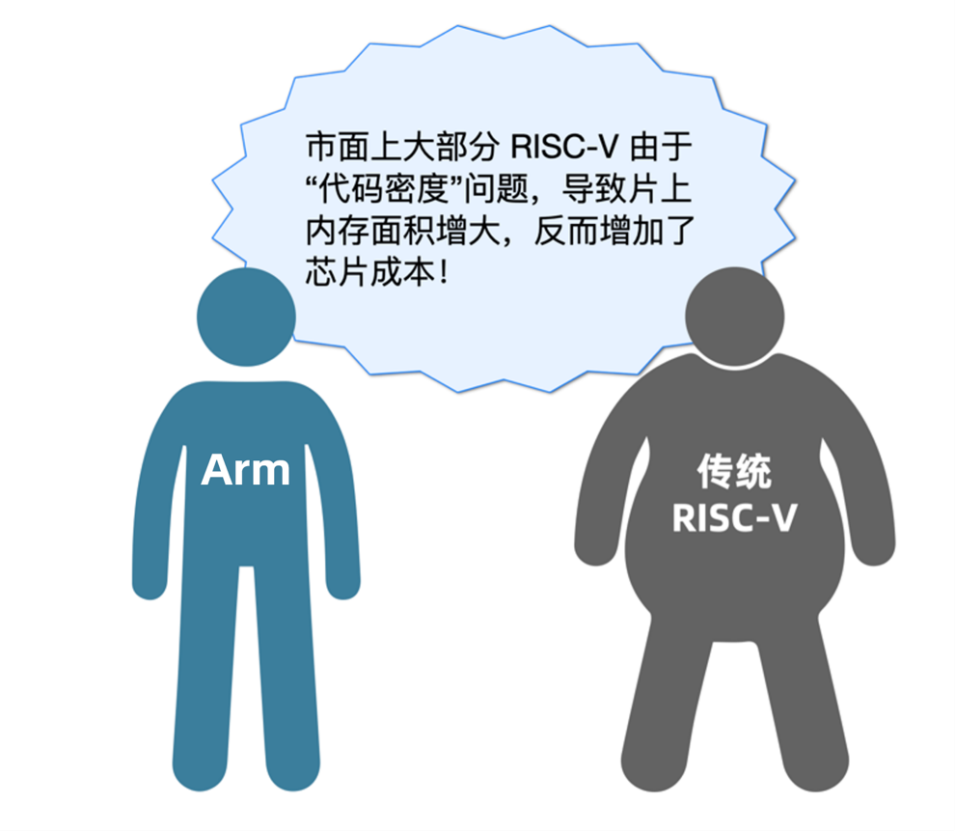
(图1)Arm 芯片与传统RISC-V 芯片对比
二、研发思路
针对以上行业痛点,隼瞻追根溯源,面向市场推出全新的代码密度增强技术方案。
组合拳一:面向应用深度优化的隼瞻处理器指令集
程序代码密度主要由处理器指令集、ABI、编译器、基础库、程序代码等部分决定,而处理器指令集(ISA)则是代码密度最根本的决定性因素。大多数嵌入式芯片, 例如 MCU,程序存储器占据了芯片50%以上的面积,采用更紧凑的指令集可以显著降低 SoC 面积。相关研究显示,嵌入式芯片有42%的能耗来自于取指,而只有6%用于执行实际的算术运算,一个更紧密的处理器指令集能产生更小的代码,从而减少从储存器取指令的消耗。
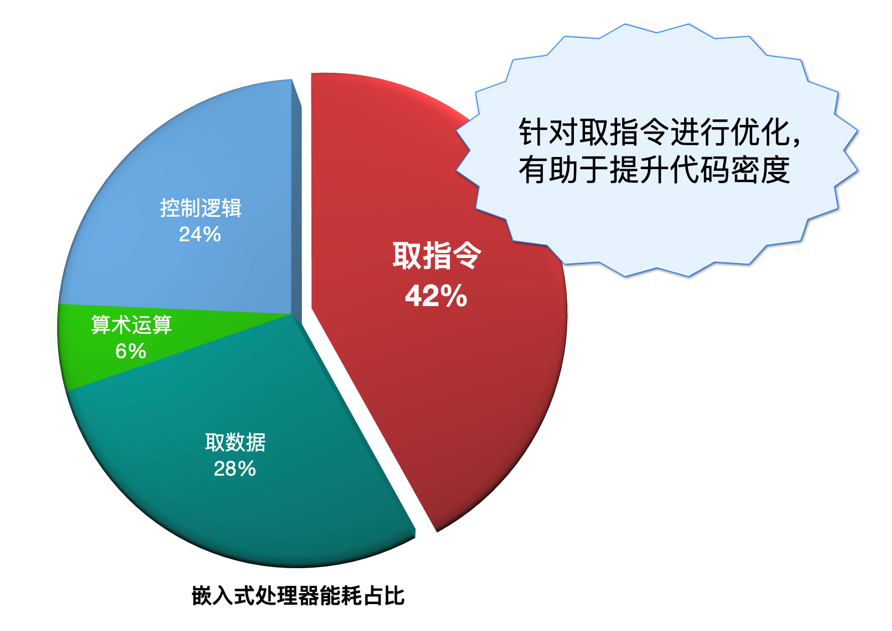
(图2)取指能耗占比图
而Arm在嵌入式成熟架构领域有着更为专业的系统设计,其中、小型 Armv-M 架构就是其典型代表作。因为它既包含了嵌入式常用操作指令的优化,同时兼备灵活、高密度的 Thumb-2 指令集,所以也顺理成章地成为当前嵌入式领域最受欢迎的架构。
RISC-V 在设计之初考虑的是嵌入式、通用计算和高性能计算等多个场景,并未针对嵌入式特有场景进行特定优化。
以一段 C 代码为例:int indexing(int *p, int offset) { return p[idx] },Arm 编译后只需要一条指令就能完成任务,但是传统的 RISC-V 指令需要3条。
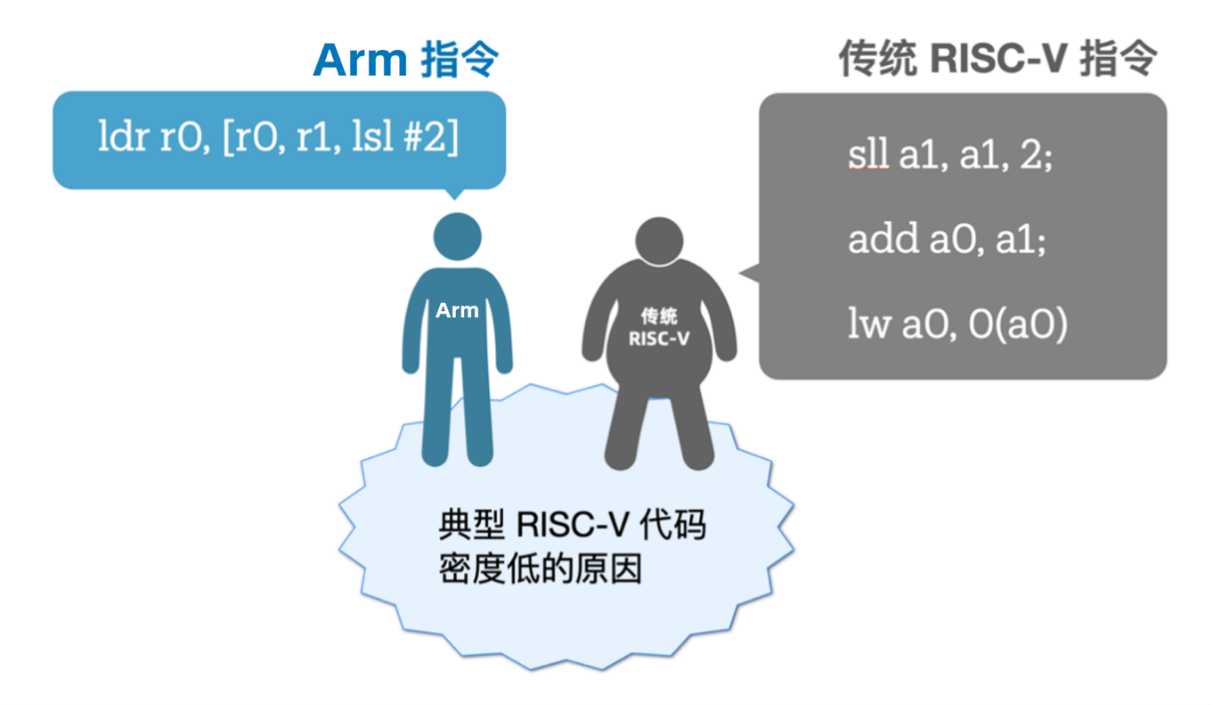
(图3)Arm & 传统RISC-V指令集对比
为解决 RISC-V 架构在嵌入式领域的应用瓶颈,隼瞻科技针对代码密度增强技术开展了全方位革新,从最源头最核心的处理器指令集进行了大幅优化。
首先,隼瞻处理器对 RISC-V 社区多年来陆续引入的 B 扩展、Zc 扩展、Zicond 等一系列标准扩展提供了有效支持。
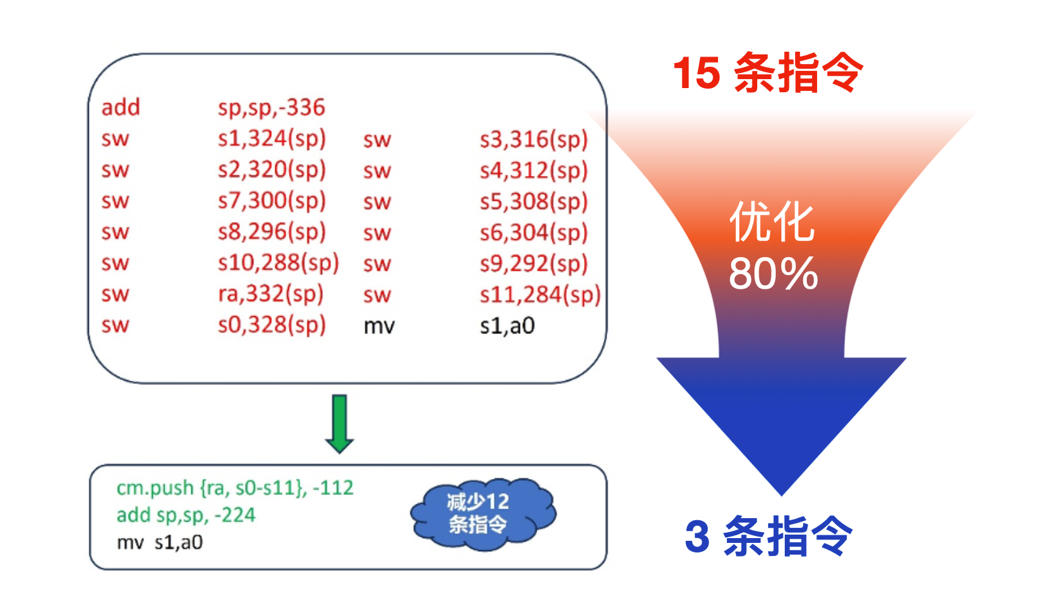
(图4)隼瞻指令集优化成效
虽然RISC-V 社区的标准扩展在一定程度上提升了代码密度,但其作用仍然十分有限。例如,在前文提到的数组寻址场景,标准扩展就无法覆盖。因此,隼瞻科技在支持常见的 Zc、B、Zicond 扩展指令集的基础上,将自主研发的代码密度增强指令 Xc 扩展加入到处理器核中,从多个方面对代码密度进行深度优化。
Xc 扩展致力于解决标准扩展忽视的场景,例如、在上述案例中用一条指令就能完成数组寻址,做到和 Arm 一样的指令密度和运行效率。
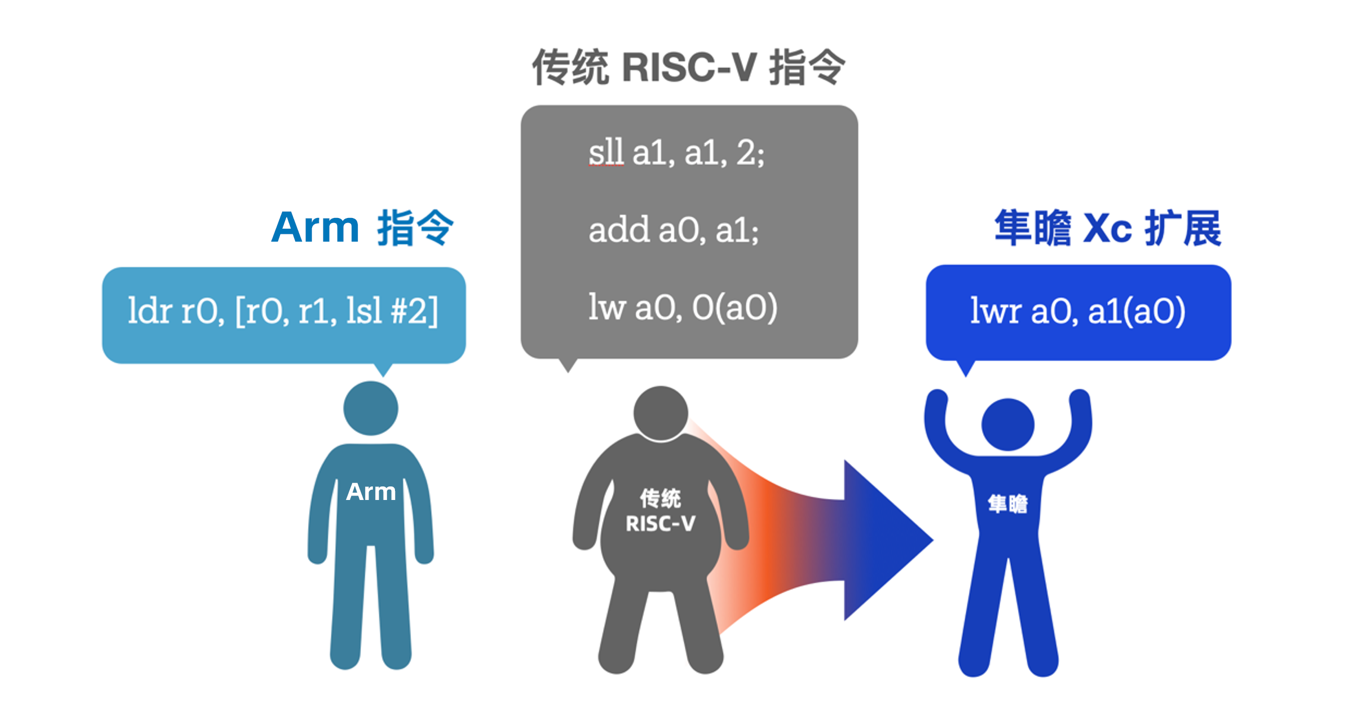
(图5)隼瞻自研Xc扩展显著提升代码密度
Xc 扩展不仅提升了代码密度,并且因为一条指令就能完成多条指令的功能,系统性能也得到了极大提升。此外,它还避免了在执行多条指令过程中不必要的寄存器分配,从而进一步优化了整体性能。
组合拳二:深耕编译器和基础库,隼瞻科技持续打造深度优化的 RISC-V 工具链
除了处理器指令集,编译器和基础库也对代码密度的最终成果有着明显影响。
Armv-M 架构生态中,商业编译器会与内核厂家深度合作,针对体系架构进行有效的指令调度,从而获得更高的代码密度,同时自带高度优化的 C 库和数学库。相关的开源编译器也因为该架构推向市场的时间较长,发展得比较成熟。
相对于成熟的Arm生态,RISC-V生态发展时间不长,优化尚不成熟,与Arm差距较为明显。
为此,隼瞻科技在追寻RISC-V生态完善的脚步中,针对自有芯片(如:Wing-M130 系列)研发出了WingGCC 编译器,解决了 GCC 作为一个从小型嵌入式系统到大型 HPC 的通用编译器长期存在的、领域针对性不强的问题。
隼瞻WingGCC 编译器完整匹配各种标准扩展指令和隼瞻自定义扩展指令,同时适配隼瞻专用高效微架构,能充分发挥处理器性能。同时,还能在兼顾性能的前提下,针对嵌入式场景使编译器重点偏向指令密度进行优化。
同样,针对嵌入式应用场景深度优化的隼瞻 WingLib 基础库,则在开源环境通用的 newlib 基础上进行了大刀阔斧式的改革。通过聚焦嵌入式应用并精简非相关代码,基于专业的汇编及体系结构能力、精确排布重点 API 的指令序列,与自定义指令集协同提升代码密度!
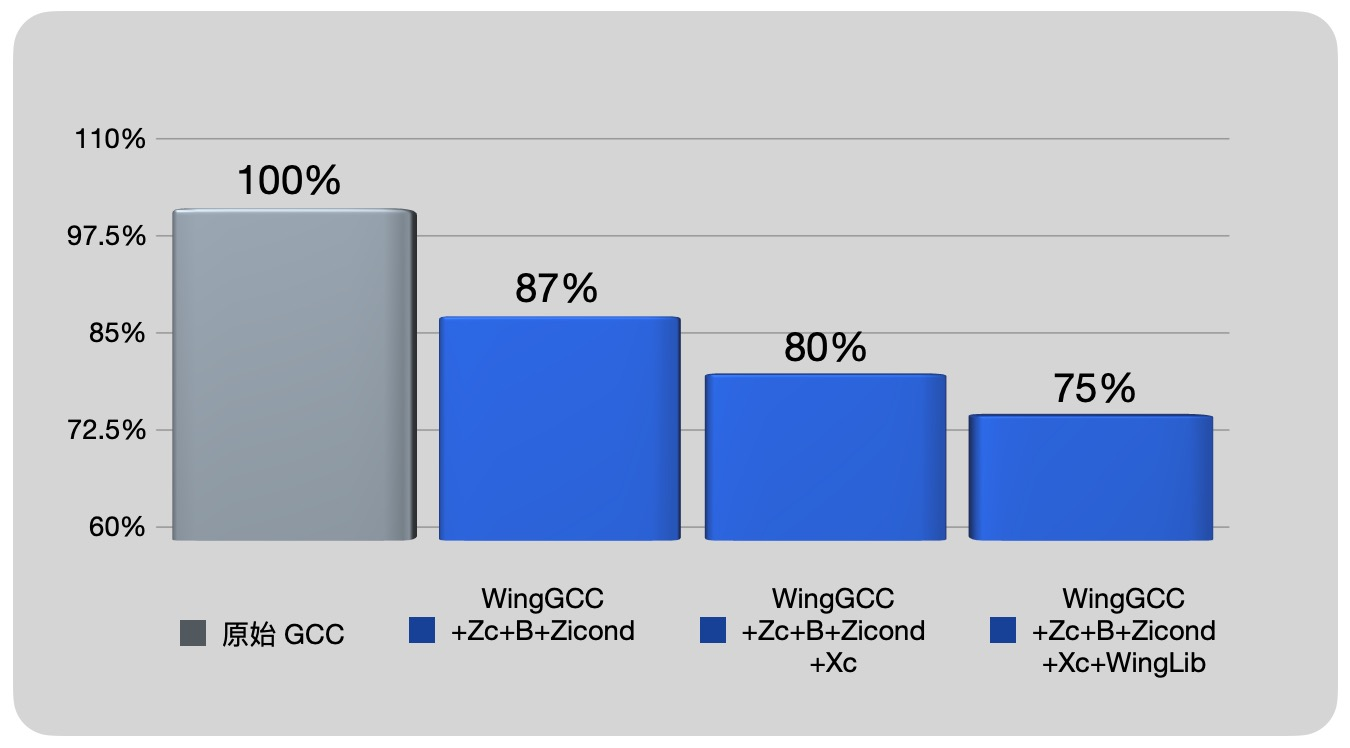
(图6)经过隼瞻的密度增强技术后代码空间的对比
通过上述一系列组合拳的优化,隼瞻科技的RISC-V处理器在Codesize方面已经与Arm架构不相上下。
Embench是嵌入式、物联网系统常用的Benchmark,重点关注处理器在不同应用场景下的Codesize。它由19个真实的程序组成,运行结束后将会产生各个程序的Codesize数据,用来评估平台和编译工具链的Codesize性能。传统RISC-V在Codesize方面并不占优势,Embench跑分长期处于被Arm压制的状况下。隼瞻科技通过自研编译工具链,已经实现在Codesize方面对Arm的反超!
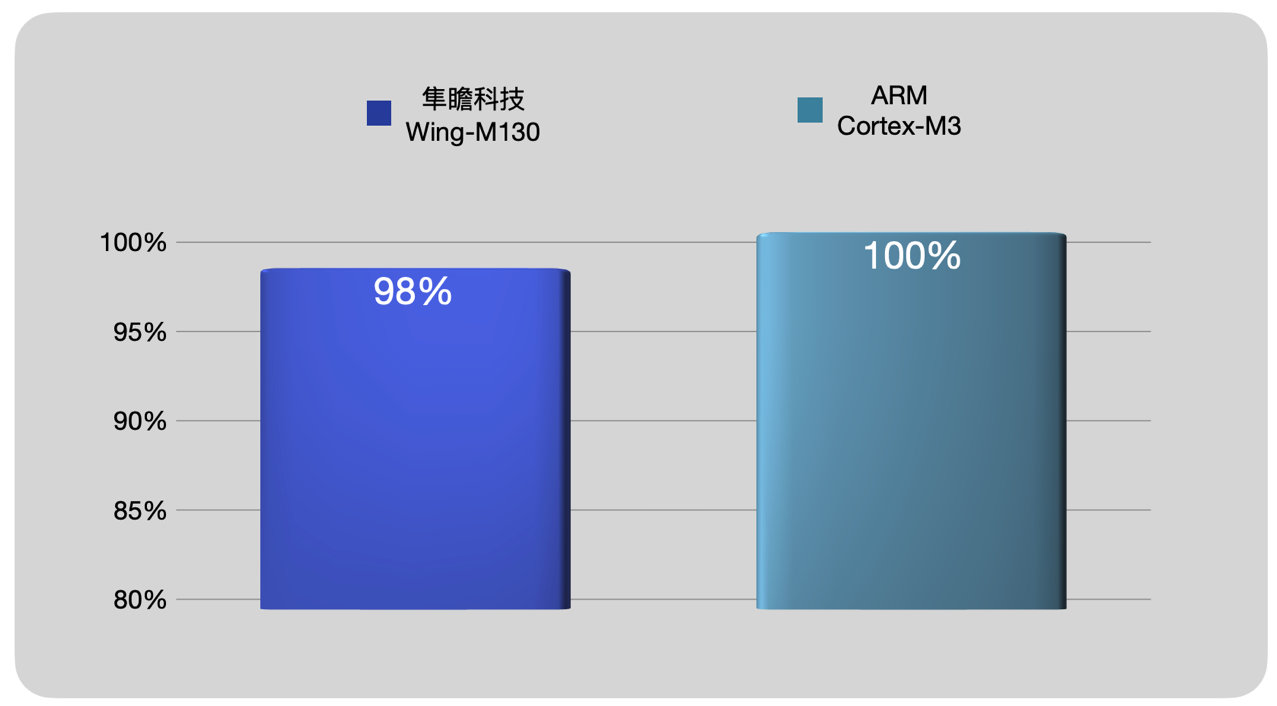
(图7)隼瞻科技Wing-M130与Arm Cortex-M3在Embench上的对比
遵循 ASIP(Application-Specific Instruction-set Processor,面向应用的定制指令集处理器)开发思路,隼瞻科技还能针对应用相关的代码进行优化,达到更高的代码密度。
以计算两张图像的 alpha 混合为例,以往需要几十条指令才能完成的 RGB 三色像素加减乘除复合计算,现在通过隼瞻WingStuido专用处理器设计平台,基于选定的基础处理器,扩展一条单周期指令就可以完成,在提升计算效率的同时,极大减少了程序代码空间。
三、应用场景
近期,有客户希望找到一颗 RISC-V 处理器对 Arm Cortex-M3 进行平替。在尝试了市面上常见的几家解决方案后,均发现代码尺寸膨胀较大,在某些场景下甚至超过了100%。由于“代码密度”问题造成的成本增加,在RISC-V替换Arm CPU过程中始终是一道难以逾越的鸿沟……
结合上述诉求,隼瞻科技针对客户的两个主要业务场景、基于 WingGCC进行初步评估,迅速实现了比市面上常见解决方案更小的代码尺寸。
使用支持隼瞻代码密度增强指令的编译器、搭配隼瞻独家编译的 WingLib 库,最终成功实现与 Arm Cortex-M3 代码尺寸相比在98%和101%的优异成绩!相对竞品、领先优势超过33%。方案一经推出、立即得到了客户高度认可,双方迅速达成合作。为此,客户成功实现了低成本、高能效平替解决方案!
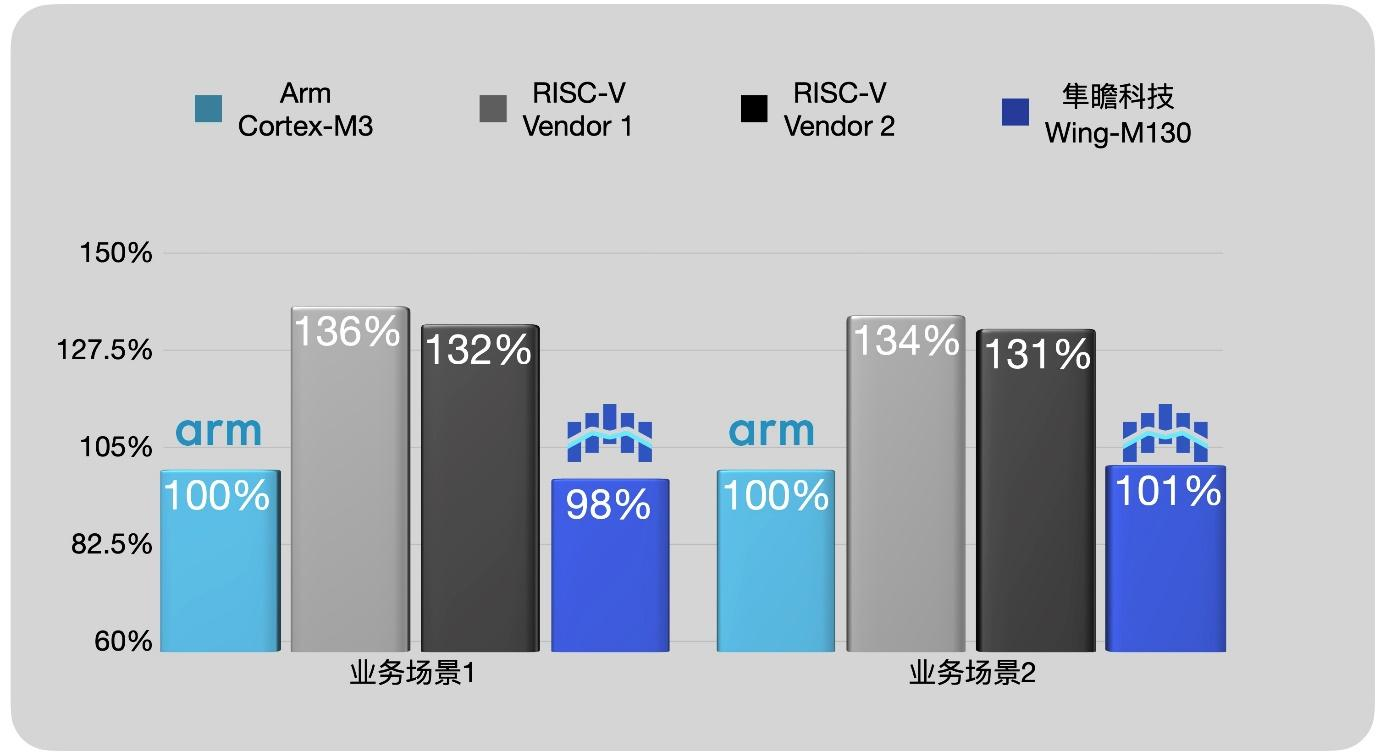
(图8)隼瞻科技领先竞品33%,与Arm架构持平
四、展望未来
隼瞻科技自研的代码密度增强技术,结合处理器指令集、编译器和基础库,面向应用深度优化的这一超级组合拳,为行业客户带来实实在在的平替助力,同时也为RISC-V生态发展提供源动力。
随着中国嵌入式芯片行业迅速发展,RISC-V生态将日渐丰富与强大!隼瞻科技将始终坚持独立探索、精益求精的态度,全力推动 RISC-V 生态走向成熟商用市场,为中国的嵌入式芯片行业创造更多可能性!!!
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。
责任编辑:kj005
文章投诉热线:182 3641 3660 投诉邮箱:7983347 16@qq.com


近年来,随着 ChatGPT、Sora 、DALL-E、Stable Diffusion、Pika等重量级应用的接连发布,Sora文生视...