科技
设为书签Ctrl+D将本页面保存为书签,全面了解最新资讯,方便快捷。
以ChatGPT、GPT-4为代表的AI应用和大模型掀起技术革命和商业浪潮,运用GPT技术为问题场景提供解决方案,成为数字经济发展的必然趋势,也加速推进了人工智能算法产业化进程。同时,BPAA第三届应用算法实践典范在上海市普陀区的正式启动,为汇聚全球算法资源、加速算法产业化进程、营建区域算法人才生态注入新势能。
作者曾在《建设公共服务算法中心 促进数字政府建设》[1]一文中,就公共服务算法中心的概念(如附图1所示)、算法中心建设的必要性、公共服务算法的构建逻辑、算法中心的运行与管理(如附图2所示)及相应的算法安全与算法责任等方面进行了详尽的解析与探索。其核心要义为:通过构建针对公共服务领域各垂直行业细分问题场景的一个个垂直应用算法模型,以实现针对具体细分问题场景的智能化解决能力(包括但不限于公共服务领域各事件的态势分析、趋势判断、预警预报等智能决策),是公共服务算法中心建设的根本所在。同时,通过将一个个的垂直应用算法模型融入进而形成公共服务算法模型库,以达到快速复用、组合创新、迭代升级、规模化地构建公共服务领域的“政务脑核”[1]的目的。最终,当公共服务算法中心的算法模型库容量越来越趋近全量公共服务领域的算法模型集合时,公共服务算法中心将趋于成熟,公共服务领域的智能服务目标将得以实现。
附图1:公共服务算法中心概念示意图
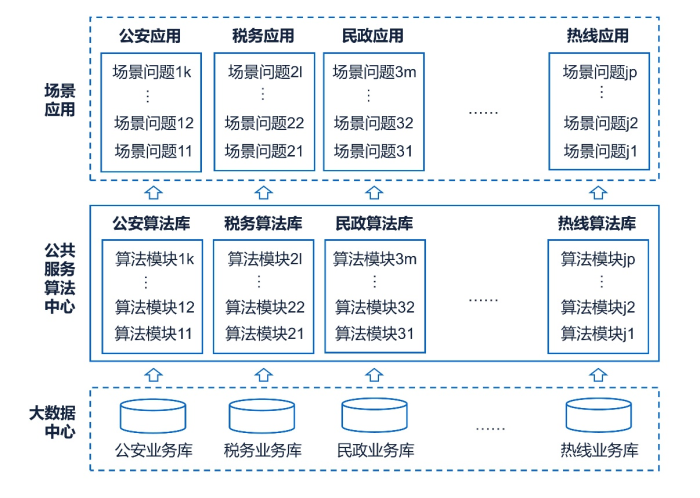
附图2:公共服务算法中心的运行与管理示意图
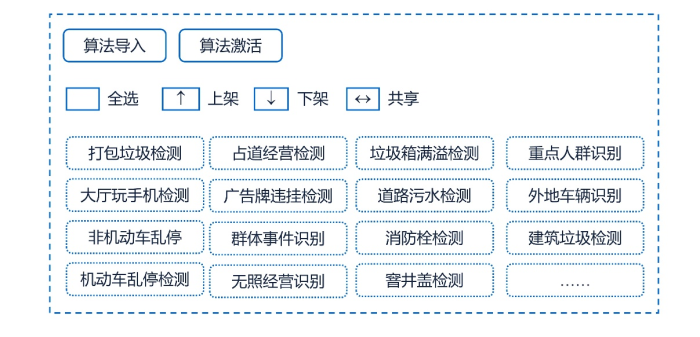
作为该文的接续,本文将对公共服务算法模型的构建方式进行探索。在预训练大模型逐渐成为人工智能开发范式的当下,本文提出:实际应用中,相较于如ChatGPT、GPT-4等跨行业的通用大模型和传统的针对特定行业各细分问题场景独立开发的小模型范式,针对垂直行业的通用“中模型”范式将是公共服务算法模型构建的较好选择。
小模型范式
在预训练大模型风潮掀起之前,小模型范式一直是人工智能开发的主要方式。所谓小模型范式,是指针对每个细分问题场景,都将独立地进行数据的采集、处理、标注、模型选择、模型训练和模型迭代等一系列开发环节。不同细分问题场景都将重复上述开发环节。以城市治理中的占道经营检测算法模型为例,通常需要针对不同区域的占道经营事件,重复进行训练数据的采集、处理、标注、模型选择、模型训练和模型迭代等工作,分别建立针对不同区域的占道经营事件的检测算法模型,并经软件开发和模型封装后投入使用,参见附图3。
附图3:小模型范式示意图
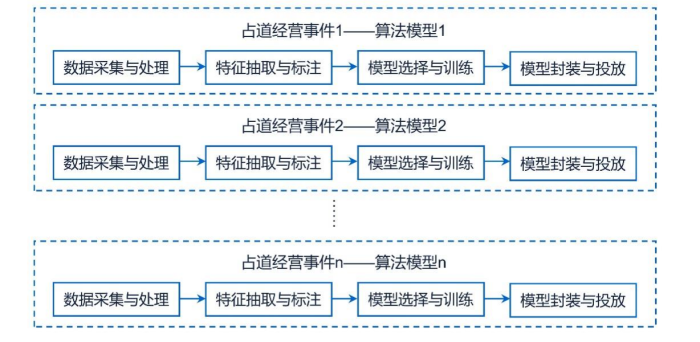
据初步测算[1],一个城市的社会治理最小颗粒问题场景将达到5万个左右。若每个细小颗粒问题场景都需要一个或数个算法模型对应,则一个城市的社会治理应用算法模型总数将达到5万多个。按我国近400个城市进行估算,则针对细分问题场景的垂直应用算法模型将达到2000多万个。
显然,小模型范式存在以下几个问题:一是开发、维护成本高。针对每一个细分问题场景都需要进行数据采集、处理、标注,都需要单独训练一个模型,这便会导致开发、维护成本高;二是开发效率低。针对每一个细分问题场景进行算法建模是一种碎片化的“小作坊模式”,因而开发效率低;三是可复用性差。由于将每个问题场景的数据进行割裂训练,产出的模型可复用性差,泛化能力弱,很难迁移到其它同类业务(如对于A区域的占道经营事件的算法模型很难迁移至B区域同类事件);四是资源消耗量大。由于每个业务都单独建模,每个模型的训练、迭代升级都需要耗费资源,因而总的资源消耗量大。
尽管小模型范式存在上述问题,但在算量(训练数据)尚未规模化增长、算力尚未充分发展之前,小模型范式是人工智能开发的主要方式。
大模型范式
近年来,伴随算量的快速增长和算力的飞速发展,一种称为“Transformer”(转换器)的深度算法框架横空出世(2017年由谷歌发明)。自2018年谷歌发布基于Transformer算法框架的BERT大模型始,各种基于Transformer算法框架的AI大模型LM(Large Model)尤其是生成式预训练大模型GPT(Generative Pre-trained Transformer)如雨后春笋般层出不穷。国外如StabilityAI公司的SD绘画大模型、谷歌的多模态多任务大模型PaLM-E和计算机视觉大模型ViT-e、Meta公司的开源语言大模型LLaMA、DeepMind公司的AphaFold等产品,国内如百度的文心大模型、阿里的M6、腾讯的混元AI大模型、华为的盘古大模型等等。特别是人工智能公司OpenAI于2022年11月30日发布的ChatGPT和今年3月发布的GPT-4多模态大模型所“涌现”的各种能力,更是点燃了各界对AI大模型的热情,越来越多的公司是如潮水般纷纷涌入。大模型现已取代小模型而成为当下人工智能开发的主要范式。
AI大模型通常是在大规模无标注数据上进行模型预训练(无监督学习),以得到一个掌握共性规律和通用知识的基础通用大模型,然后再在特定子任务的小规模有标注数据上进行模型微调(监督学习),以得到针对特定子任务的智能服务算法模型。
按此思路,对于公共服务算法模型的构建,我们可以直接选择一个较为成熟的基础通用大模型(或基于开源模型方式,或通过模型API接口调用方式),如ChatGPT或GPT-4或其它,然后再针对公共服务领域的特定子任务(如某一具体占道经营事件)的小规模有标注数据进行微调,以获得针对特定子任务的算法模型。如附图4所示。
附图4:大模型范式示意图
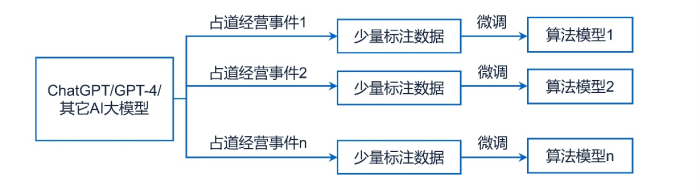
相比小模型,大模型范式在开发效率、开发和运维成本、模型的泛化能力、模型的精确性、落地应用的便捷性等方面都具有显著优势。
中模型范式
ChatGPT、GPT-4或类似的基础通用大模型,其核心是智能算法技术的规模集成与生成能力的汇聚,即在大量预训练的基础上,形成生成数据、生成程序、生成模型的能力,在变量与模型越丰富的情况下,它的学习、纠偏、优化能力会越来越强,从而体现出不断成长的卓越智能。然而,这种能力必须依赖于对海量数据的训练和强大算力的消耗。这意味着,如果将ChatGPT或GPT-4类似的基础通用大模型直接应用于问题场景,不仅要在算力、算量和相应的系统上大量投入,还需对模型(算法)开发和模型管理系统建设大力投入。
事实上,在应用层面上,以有限多数据源可调度可访问可读取为主的“中数据”、若干关键问题解决模型集成的“中模型”、服务于中数据与中模型需要而形成的“中算力”,是在当前现实的数字能力下用好GPT技术与其他算法技术,推动人工智能从基础建设走向应用服务的关键。这将有助于形成数字治理意义上的“中政府”和数字经济中的“中企业”群体[2][3]。
在垂直领域调度数据、汇集专业经验、预训练大量专有模型并持续集成到中模型的规模与水平,这可能是将大模型范式应用于垂直应用领域行之有效的思路,即针对垂直行业的“中模型”范式(参见附图5),这也与零点有数持续倡导在系统平台基础上建设云脑脑核的理念一脉相承。
附图5:针对垂直行业的中模型范式
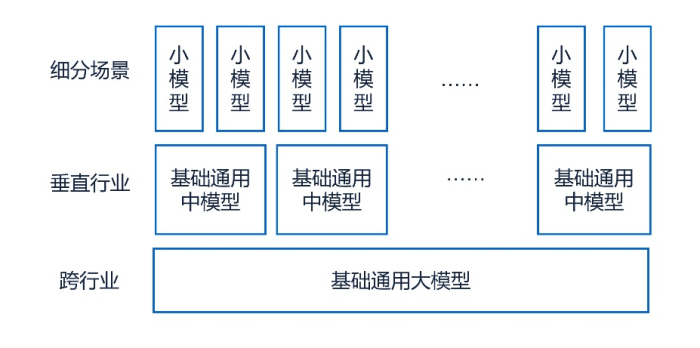
对于公共服务,整体上可以看作一个垂直领域,从而理论上可以构建一个公共服务领域的基础通用中模型(简称“政务大模型”或“政务GPT”,以下同),然后再结合特定子任务小规模有标注数据(如占道经营事件数据)进行微调,以得到针对某一特定子任务(如各占道经营事件)的算法模型,参见附图6示意。
附图6:中模型范式示意图
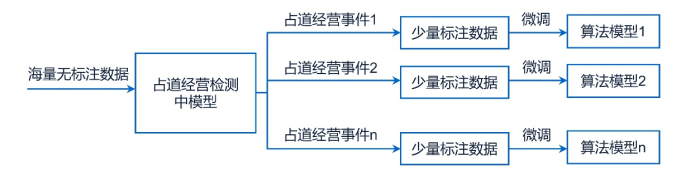
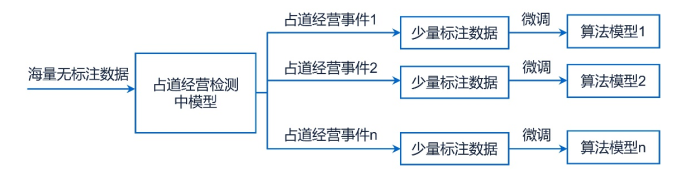
考虑到公共服务领域仍然存在诸多不同性质的细分行业,有的属于服务型的,有的属于监管型的。同时考虑到数据壁垒可能导致的语料信息的采集难度以及不同信息安全等级要求的不同监管要求,可考虑进一步细分到以某一事件类型为对象的通用中模型建设。
仍然以占道经营检测为例,首先可以对不同区域不同占道经营事件所蕴含的共性规律进行提炼,建立一个关于占道经营事件检测的通用算法中模型,然后再根据不同区域不同占道经营具体情况进行微调(将普遍规律与特殊情况相结合),获得针对不同区域不同占道经营事件的检测算法模型(参见附图7示意)。
附图7:中模型范式示意图
相比小模型范式,中模型范式在开发效率、开发和运维成本、模型的泛化能力、模型的精确性、落地应用的便捷性等方面都具有显著优势;相比如ChatGPT、GPT-4或类似的基础通用大模型,中模型又极大地降低了对算力、算量和相应的系统上的投入门槛,同时有利于提高模型的准确性、专业推理能力和迭代升级效率。
公共服务算法模型的构建离不开算力和算量(数据)的支持,算法模型的迭代升级,将会对算力和算量提出更高的要求。各地在《全国一体化大数据中心协同创新体系算力枢纽实施方案》(发改高技〔2021〕709号)指导下正在快速推进全国一体化算力网络和现有数据中心的改造升级等建设工作。
新一代数据中心应该建立在问题场景导向上,以算法模型中心为应用核心,重视投入大量应用问题解决模型的预训练,以及相关算法模块的可移用、可组合、可集成技术开发,在有限问题领域、有限数据源、有限实用模型基础上配置适当的有限算力,从而构建出具有重要问题领域实际问题解决能力的中模型算法中心,以此对应相应的数据源整理与可能的汇融、建立与更多独立数据源之间的接口关系和调度机制、建立数据的兜底与补丁机制,从而建立新一代有实际问题解决能力的新型数据中心[4]。
新一代数据中心的建设必然具有需要深入透视业务工作、涉及问题场景细碎多样、模型预训练工作浩繁、对于人员复合能力要求极高、对应的预算投入细碎复杂这些问题,因此建设这样的数据中心势必会与数据中心建设技术开发领域的既得利益集团发生冲突,因为他们的目的在于大量推销复制以数据中心、智慧城市、智慧行业与智慧领域为名的标准化数据管理、数据治理、数据展示系统产品、平台产品,在规模化定价的基础上挤压消耗掉很多城市、地区、开发区和政务部门本来期待用于智能化解决特定问题的预算,用他们熟悉、成熟但不敷当前使用的数字化技术占据了数据管理和服务领域有限的立项资源,而且针对相关数据与数字经济管理部门对于数据技术掌握的有限性,形成对工作系统功能设置、接口设置、服务优化和升级优化的任性安排和技术要 挟,各地数据中心建设正面临着和很多政府工程项目类似甚至更严重的“工程项目通病”。
智慧政府和智慧城市要走向真正的智慧,现在已经到了需要认真考虑形成模型算法建设规划、应用模型建设步骤与成效检验、模型算法驱动的数据中心建设的独立预算投入与招标机制、基础系统与算力算量系统之间的全接口开放管理机制、以基层和作业面成效来衡量智慧机制的效用和可交付性的时候。
只有在这种理念下,公共服务算法模型的构建思路才能付诸实施。(作者:零点有数董事长袁岳、零点有数副总裁许正军)
责任编辑:kj005
文章投诉热线:156 0057 2229 投诉邮箱:29132 36@qq.com












