科技
设为书签Ctrl+D将本页面保存为书签,全面了解最新资讯,方便快捷。

本文探讨了社区搜索问题,其核心在于大型网络中识别与特定查询节点紧密相关的子图(社区)。这一任务在社交网络分析等多个领域扮演着基础而关键的角色。传统方法固定规则和结构约束限制了对复杂或上下文相关社区模式的识别能力。因此,研究者开始转向更为灵活和强大的深度学习方法,以期克服这些限制并提升社区搜索的效果。在现有的深度学习方法中,判别式方法如ICS-GNN和QD-GNN通过节点分类或结合局部查询依赖结构与全局嵌入来优化社区评分。这些方法的优势在于能够充分利用已有的结构信息进行精确预测,但它们在捕捉全局社区模式方面存在不足,并且对标注数据的依赖性强,难以从少量样本中学习。另一方面,生成式方法如SEAL和CommunityAF能够模拟社区分布并自回归地生成节点,适合处理复杂、非线性的社区结构。然而,这些方法在训练过程中对顺序敏感,推理效率较低,并且在将连续表示转换为具体社区成员时面临挑战,通常需要采用固定的阈值进行离散化,这可能影响结果的准确性。扩散模型在生成高质量数据方面展现出卓越的性能,但在社区搜索领域的应用仍面临诸多挑战,尤其是在适应性、计算效率以及如何有效地将连续输出转化为离散社区成员等方面。
本文提出了一个新的框架——CommunityDF,它通过将社区搜索问题视为条件图生成任务,提出了一种新的方法论。在这个框架中,给定一个查询节点和一个底层图结构,目标是生成一个与查询节点紧密相关的子图(社区)。这种方法将社区搜索问题转化为一个条件概率分布问题,即学习在给定查询节点和底层图结构的条件下,生成社区成员节点状态的概率分布。
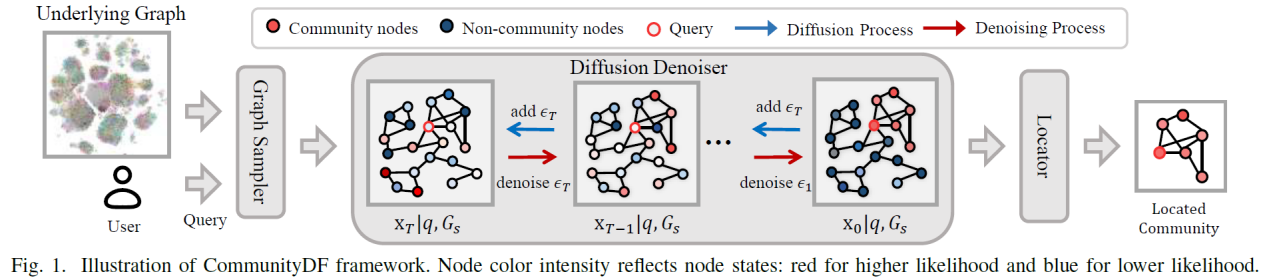
在CommunityDF中,每个节点的状态表示其属于查询节点相关社区的可能性。通过DDPMs,模型逐步添加噪声到节点状态中,模拟数据的扩散过程,然后学习如何逆转这一过程以恢复原始的社区结构。这个迭代的去噪过程允许模型灵活且稳定地建模社区中的复杂模式,而不需要依赖于节点生成的顺序(Fig.1)。
在CommunityDF的实验评估中对七个真实社交网络数据集进行测试,结果显示,CommunityDF相比现有方法在性能上提升了16%-47%。 此外,我们不仅提供了算法的理论验证,还提出了两种获取粗略社区的方法,显著提高了计算效率并增强了结果的质量。通过这些改进,CommunityDF不仅能够高效处理大规模网络中的社区搜索问题,还在多个实际数据集上展示了卓越的表现。
总的来说,CommunityDF是首次将去噪扩散概率模型(DDPMs)应用于社区搜索问题的工作,为该领域带来了创新性的进展,具有重要的推动意义。通过利用这些多样化且广泛认可的数据集,CommunityDF证明了其在不同类型的网络结构中广泛应用的潜力,为用户营销提供了深入洞察,使企业能够识别和利用关键影响力节点,细分市场,预测用户行为,优化内容策略,并评估营销效果,从而实现更精准、高效的目标用户接触和品牌信息传播。
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。
责任编辑:kj005
文章投诉热线:157 3889 8464 投诉邮箱:7983347 16@qq.com


IEEE International Conference on Data Engineering (ICDE) 是数据库研究领域历史悠久的国际会...
IEEE International Conference on Data Engineering (ICDE) 是数据库研究领域历史悠久的国际会...







