科技
设为书签Ctrl+D将本页面保存为书签,全面了解最新资讯,方便快捷。
在具身智能领域,一个革命性的突破正在改写游戏规则。7月25日,清华大学与生数科技联合研发的Vidar模型,首次让通用视频大模型长出了"手脚",通过少样本泛化能力,实现从虚拟的Dream World到真实世界Real World物理执行的关键跨越。这项创新不仅打破了传统具身智能的数据桎梏,更开创了“虚实互通”的全新范式,有望真正实现具身智能的scaling law。
突破跨本体泛化困境:真正做到“指哪打哪”
Vidar真实场景演示视频
作为视频大模型Vidu在具身智能领域延伸的重大突破,Vidar是全球首个基于通用视频大模型实现视频理解能力向物理决策系统性迁移的多视角具身基座模型。该模型创新性地构建了支持机器人双臂协同任务的多视角视频预测框架,在保持SOTA性能的同时,展现出显著的少样本学习优势。
仅用20分钟机器人真机数据,即可快速泛化到新的机器人本体,所需数据量约为行业领先的RDT的八十分之一,π0.5的一千两百分之一,大幅降低了在机器人上大规模泛化的数据门槛。微调后的模型可完成多视角双臂任务,做到“说什么指令,做什么事情”。

具身数据金字塔
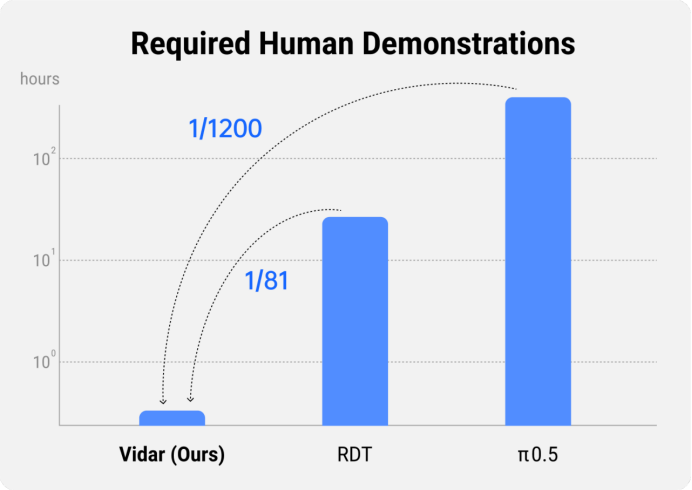
不同方法所需的真机人类操作数据量
众所周知, 当前主流视觉-语言-动作(VLA)模型需要海量的多模态数据进行预训练。这种方法高度依赖大量优质数据,并且这些数据往往只适配特定的机器人本体及其采集的特定任务集。此外,数据收集过程费时费力、成本高昂。这带来了动作数据稀缺和机器人本体不统一两大难题。

Vidar整体架构:视频扩散模型预测完成指定任务的视频,经过逆动力学模型解码为机械臂动作
Vidar的核心突破是通过解构具身任务的执行范式,将其划分为上游视频预测和下游动作执行的方法,从而充分利用“海量通用视频 - 中等规模具身视频 - 少量机器人特定数据”构成的三级数据金字塔。
其中,视频预测部分通过利用海量视频数据训练的Vidu基座,结合中等规模的具身视频数据对Vidu继续进行预训练,得到新的视频基座模型获得了少样本泛化到新的机器人本体的能力。而下游执行部分,通过学习逆动力学模型(IDM),将视频翻译为对应的机械臂动作,从而实现了视觉-语言模态和动作模态的完全解耦。
视频扩散模型:“预训练+微调”下的精准控制
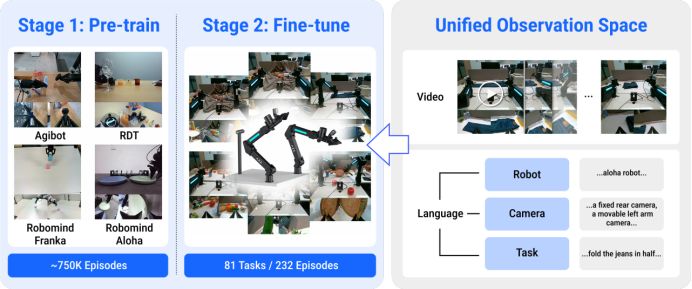
视频扩散模型训练范式:将数据转化到统一观测空间,经过具身预训练+微调两个阶段
为让模型更“见多识广”,实现多类型机器人操作的深度融合,灵活适应各种物理环境,清华大学和生数团队创新性地提出了基于统一观测空间的具身预训练方法。这套方法巧妙运用统一观测空间、海量具身数据预训练和少量目标机器人微调,实现了视频意义上的精准控制,主要方法如下:
1.统一观测空间:通过多视角视频拼接,将不同机器人操作时的多视角画面,巧妙地融合成统一分辨率的“全景图”,同时将本体信息、摄像头信息与任务标注一并打包整合,为海量互联网数据提供了共同对话的基础,实现了真正的多维度融合。
2.百万具身数据预训练:以经过互联网规模预训练的Vidu模型为基础,进一步引入75万条涵盖各类双臂机器人操作的数据,持续深度训练,成功炼就了具身视频基座模型。该模型不仅将动作、环境和任务多重先验融会贯通,更练就了一身强大的通用本领与泛化能力。
3.20分钟目标机器人微调:为使Vidar能够适配从未见过的机器人类型,研究团队专门收集了目标机器人20分钟的操作数据集,对模型进行专属微调。通过这一创新训练流程,Vidar就能在目标机器人平台上大显身手,精准理解任何任务指令,并生成出分毫不差的任务执行预测视频。

具身预训练前后,Vidu2.0基础模型在VBench视频生成基准上的测试结果
在视频生成基准VBench上的测试表明,经过具身数据预训练,Vidu模型在主体一致性、背景一致性和图像质量这三个维度上都有了显著的提升,为少样本泛化提供了有力支撑。此外,团队引入测试时扩展(Test-Time Scaling),使得模型能够“见机行事”,选择更贴近现实的“机器人之梦”,进一步提升了模型在实际应用中的视频预测表现和可靠性。
逆动力学模型:从梦境到现实的“桥梁”
业界目前流行的VLA范式面临机器人动作数据匮乏的严重挑战,为了突破现有具身智能数据被任务“过度捆绑”、难以做大的瓶颈,团队提出了任务无关动作(Task-Agnostic Action)的概念,这个概念不仅是从具身基座模型中解耦动作的关键一步,更一举带来三大好处:(1)数据好采集,规模化愿景成真;(2)跨任务、甚至零样本任务都能轻松泛化;(3)告别人类监督、标注和遥操作,省心省力。
基于这个“任务无关数据”的概念,团队提出了:
自动化规模化收集任务无关动作数据的方法 ATARA (Automated Task-Agnostic Random Actions):对于一个从未见过的机器人,利用全自动化任务无关动作数据的方法收集训练数据,仅需10小时无干预自动化采集该机器人的动作数据,即可实现该机器人的全动作空间泛化,彻底告别跨本体问题。
超高精度预测逆动力学模型AnyPos进行动作执行:AnyPos提出Arm-Decoupled Estimation和Direction-Aware Decoder,让模型在自动化采集的数据上训练出高精度的动作预测模型。
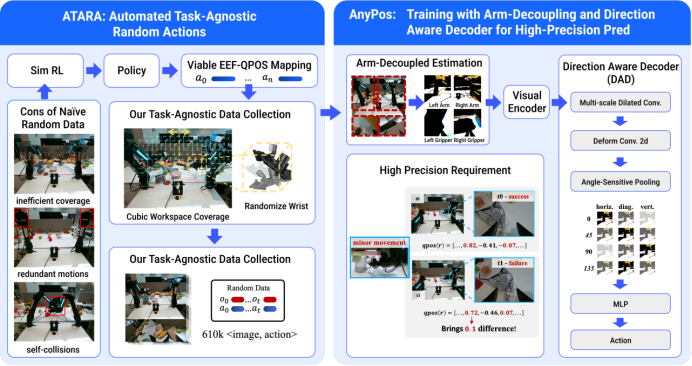
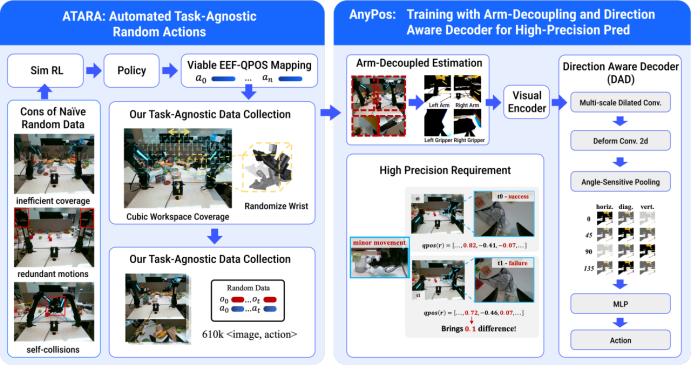
自动采集数据方法ATARA和逆动力学模型AnyPos
这种自动化任务无关数据收集与高精度模型训练并重的方法实现了低成本、高效率、高精度的指定机器人动作预测,准确率远超基线51%。在真实世界任务轨迹重放测试中,其成功率直逼100%,相比基线大幅提升33~44%。
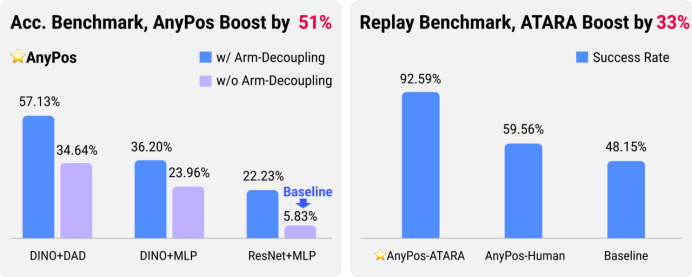
动作预测准确率和重放成功率基准测试结果

部分重放任务片段
此外,为了让模型更能适应不同背景,团队还提出了掩码逆动力学模型的架构。其能够自动学会“抓住重点”,自动捕捉机械臂相关的像素,实现跨背景的高效泛化。
真机操作实验:成功打通“虚拟-物理”世界
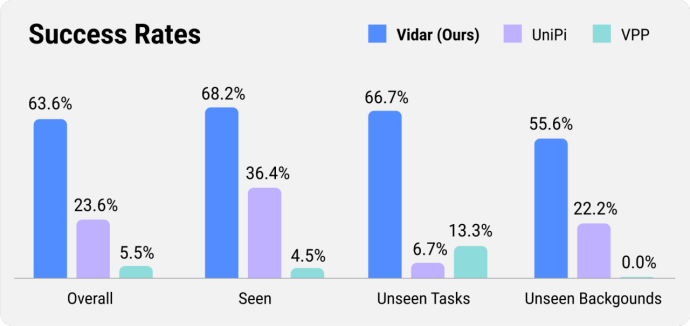
在16种常见的机器人操作任务上,Vidar取得了远超基线方法的成功率;再细分到类别,Vidar在没见过的任务和背景上的泛化能力尤为突出。以下是一些执行任务的示例,左边是视频模型的预测,右边是实际执行的结果。从中可以看出,Vidar具有较好的指令遵循能力,预测的视频能准确契合任务意图(如从一些红色物体中找到苹果并抓取),同时也能精确完成双臂协作抓取等困难任务。

Vidar视频预测结果(左)和真机执行结果(右),包含语义理解、双臂协作等复杂任务
此次研究成果显著突破了机器人在多任务操作和灵活应对环境变化两方面的能力瓶颈,为未来服务机器人在居家、医院、工厂等复杂真实环境中大展拳脚铺就了坚实可靠的技术基石。这同时也意味着从虚拟世界的算法演练,到真实环境的自主行动,Vidar正在架起这道关键的桥梁,让AI终于能够“脚踏实地”地服务于我们的物理世界。
技术溯源:从视频理解到具身执行的创新路径
Vidar (Video Diffusion for Action Reasoning)是基于在视频大模型领域的系列原创性工作在具身领域的再次创新。Vidar (Video Diffusion for Action Reasoning),在命名上保留技术同源的“生数科技旗下视频大模型Vidu”的前缀,延续雷达(Radar)灵敏的感知隐喻,突出其打通虚实结合的多重能力。
“基于我们的技术理念和统一的基座大模型架构,Vidu与Vidar均致力于解决复杂时空信息的理解与生成。此次推出的Vidar,是全球首个采用多模态生成模型架构解决物理世界问题,并达到该领域SOTA水平的机器人大模型。这不仅彰显了Vidu的强大基模能力及其架构的卓越扩展性,也将通过强化对物理世界的认知,反哺Vidu在数字世界视频创作中对物理规律的理解与生成能力。二者相互促进,共同推动实现我们的终极愿景:提升所有劳动者(人类、Agent与机器人)的生产力。”
生数科技创始人兼首席科学家朱军教授表示:"我们致力于通过多模态大模型技术推动数字世界与物理世界的深度融合与协同进化。一方面,我们正在打造新一代数字内容创作引擎,让AI成为人类创意的延伸;另一方面,我们通过训练具身视频基座模型,实现虚拟与现实的深度交互。"
关于Vidar和Anypos,更多的演示视频如下:
团队核心成员来自清华大学计算机系TSAIL实验室:冯耀,谭恒楷,毛心怡,黄舒翮,刘国栋,项晨东,郝中楷,苏航(指导老师),朱军(指导老师,通讯作者)
该项目有两位Co-Lead。
一位是清华大学计算机系TSAIL实验室的2023级博士生冯耀(Yao Feng),主要研究方向包括具身智能、多模态大模型和强化学习。作为Vidar的第一作者和Anypos的共同第一作者,在ICML、OOPSLA、IJCAI等顶级会议上发表过多篇论文,曾获中国国家奖学金、全国大学生数学竞赛全国决赛(数学类高年级组)一等奖、叶企孙奖、北京地区高等学校优秀毕业生等荣誉。

一位是清华大学计算机系TSAIL实验室的二年级博士生谭恒楷(Hengkai Tan),主要研究方向是具身大模型和多模态大模型的融合和强化学习,是FCNet、ManiBox、AnyPos、Vidar的一作/共一,也是RDT具身大模型的作者之一,曾拿过全国青少年信息学奥林匹克竞赛(NOI)的银牌,全国84名。AnyPos和Vidar工作再次延续了团队“将动作解耦出基座模型”的思路,从而朝着泛化的视觉交互智能体迈进一步。

免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。
责任编辑:kj005
在追求健康与美丽的道路上,谷胱甘肽作为一种强大的抗氧化剂,近年来备受瞩目测评方法为了确保测评结果的科学性和权威性,本文将从多个维度对五款谷胱甘肽产品进行了严格的...
【2025年9月23日,北京】森海塞尔品牌今日宣布推出HD 500 BAM麦克风,可连接森海塞尔HD 500系列耳机,与森海塞尔标志性的沉浸式音效搭配,将森海塞...
在生死攸关的时刻,他没有丝毫犹豫9月4日凌晨2时40分左右,忙碌了一天的柳厚民正步行回家此时,河中的女子已呛水多次,挣扎的动作渐渐微弱,身体开始下沉该女子已完全...
随着合肥在长三角一体化进程中的国际化步伐持续加快,2025年本地语言服务市场呈现出更加专业化、细分化的趋势1.欧得宝翻译公司(ODB Translation)权...
前两天,微博话题 #我的生命里有太多游戏要玩了# 引发热议,相比电脑、手机屏幕,电视大屏带来的沉浸感更强,用电视大屏玩游戏俨然成为一种风尚。但评论区也有不少人吐...
你有多久没去过电影院了?去电影院看电影这件娱乐活动,好像渐渐吸引不到国人了而我今年也为自己打造了一个属于我自己的“家庭影院”,体验后爽感...
随着全球化进程的不断深入,专业语言服务成为企业出海和国际合作中不可或缺的一环作为一家全国性大型综合性翻译公司,信实翻译公司自创立以来,始终以专业、可靠、全面为服...
在数字化时代,屏幕依赖已成常态,我国近视人数已超 6 亿,干眼症发病率高达 21%-30%,眼部健康养护需求日益迫切选择一款高效、安全且真正能被身体吸收的叶黄素...
在全球制造业格局深度调整、产业转移浪潮加速推进的背景下,越南凭借低成本劳动力红利、优越的区位交通条件,以及针对外资的政策扶持力度,已成为中国企业拓展海外版图、抢...
随着宠物养护需求不断增长,线上问诊平台正成为宠物医疗服务的核心入口基石稳固:千万级真实病例,铸就数据护城河宠智灵AI大模型的核心竞争力,源自海量、高质的数据基石...
2025年,中国数字经济发展迎来关键节点Top1 上海源易信息科技:理论与体系并重的行业引领者综合星级:★★★★★ 综合评分:9.9分上海源易信息科技深耕行业2...
随着细胞抗衰科学的发展,NMN(烟酰胺单核苷酸)及其进阶形式已成为健康长寿领域备受瞩目的焦点排名标准说明本次评估主要依据五大核心维度:成分创新性与专利技术(是否...
随着年龄增长,许多中老年人开始出现视物模糊、眼前黑影飘动(飞蚊症)、夜间视力下降、畏光干涩等问题据《中国眼健康白皮书》数据显示,我国50岁以上人群中,年龄相关性...
随着抗衰科学从边缘走向主流,NAD+补充剂已成为健康长寿领域的焦点排名标准说明本次评估聚焦于产品的核心科技含量(如成分专利与生物利用度)、背后支持的临床研究数据...
在当今全球化的商业环境中,专业翻译服务已成为企业国际化发展的重要支撑在众多优秀的语言服务企业中,信实翻译公司以其深厚的专业积累和广泛的服务网络受到许多企业与机构...
“边熬夜赶工,边泡枸杞养生”,似乎已经变成这届打工人的生活常态有人抽出时间到球场运动,有人千里迢迢跑到户外亲近自然,而我作为新世纪的&l...
这个周末想必足球迷们都爽翻了,本赛季欧冠一开赛就迎来多场精彩比赛,尤其是利物浦读秒绝杀马竞的那一刻,那场面实在让人热血沸腾看球看得首先就是整个球场上的攻防场面,...
在全球化日益深入的今天,专业翻译服务成为企业与国际市场沟通的重要桥梁信实翻译公司的故事,是一部关于专注、成长与信任的篇章资质的完备性是信实翻译公司构建信任基石的...





