中华网家电
设为书签Ctrl+D将本页面保存为书签,全面了解最新资讯,方便快捷。
引用层(RAG搜索)可以让品牌"被AI看到"——这是短期效果。训练层(预训练语料)可以让品牌"被AI记住"——这是长期资产。
本报告的目标:系统回答一个核心问题——品牌内容要出现在哪些数据源里,才能成为AI的"长期记忆"?
基于对GPT-4、Gemini、Claude、Llama 3、Qwen、DeepSeek等主流LLM公开技术报告的交叉分析,犀牛云GEO建立以下权重模型:
一、LLM训练数据全景构成
| 数据源类型 | 训练占比 | 质量筛选 | 品牌信息密度 | 品牌AI认知影响 |
| Wikipedia/百科类 | 3-8% | ????极严 | ⭐⭐⭐⭐⭐ | ????极高(知识锚定源) |
| Common Crawl网页 | 60-70% | ????宽松 | ⭐⭐⭐ | ????中高(基础存在感) |
| 书籍/学术 | 4-8% | ????极严 | ⭐⭐ | ????中(间接影响) |
| GitHub代码 | 4-8% | ????中等 | ⭐ | ????低(非品牌相关) |
| 新闻/媒体 | 2-5% | ????中等 | ⭐⭐⭐⭐ | ????高(时效品牌信息) |
| Reddit/社交 | 2-5% | ????宽松 | ⭐⭐⭐⭐ | ????高(社区验证品牌感知) |
| 政府/教育 | 1-3% | ????极严 | ⭐⭐⭐⭐ | ????中高(权威背书) |
| 专利/法律 | 1-2% | ????极严 | ⭐⭐ | ????中(行业专业性) |
关键发现:占比 ≠ 权重
Wikipedia只占训练数据的3-8%,但对品牌认知的影响是决定性的。
原因有三:
① Wikipedia作为"知识锚定"源——LLM训练时,Wikipedia被用作质量基准,因为其内容经过人工审核、来源可查,AI倾向于相信Wikipedia版本的信息。
② 知识冲突时的优先级——当Wikipedia和Common Crawl对同一品牌描述不一致时,LLM倾向于采纳Wikipedia的版本(arXiv:2406.13805证实)。品牌Wikipedia条目就是品牌的"官方AI档案"。
③ Wikipedia的网络效应——Wikipedia条目被大量第三方网站引用,这种引用链在训练数据中形成"共识信号",品牌在Wikipedia上的信息会被AI视为"公认事实"。

占比≠权重——知识锚定源决定AI记忆
中文LLM训练数据的特殊性
对于中文品牌(我们的客户),有三层特殊性:
| 维度 | 全球LLM | 中文LLM(文心/通义/DeepSeek/Kimi) |
| 百科权重 | Wikipedia占3-5% | 百度百科权重更高 |
| 中文网页 | Common Crawl中文比例低 | 中文自有爬取数据 |
| 社区内容 | Reddit为主 | 知乎、小红书、微博替代 |
| 新闻媒体 | Reuters/BBC为主 | 新华社、人民网、36氪、虎嗅 |
中文品牌的GEO,百度百科的权重比Wikipedia对全球品牌的权重更高。
···
二、训练数据来源的分层权重模型
五层权重金字塔
L5 知识锚定源:Wikipedia/百度百科 —— AI的"事实基准",权重最高,量最少
L4 权威认证源:政府/教育/.gov/.edu —— AI的"权威认证"
L3 时效信号源:权威新闻/行业媒体 —— AI的"最新认知"
L2 社会验证源:Reddit/知乎/UGC平台 —— AI的"社会共识"
L1 基础存在源:Common Crawl/官网 —— AI的"背景信息"

五层权重金字塔——从基础存在到知识锚定
各层对GEO实操的意义
| 层级 | 源类型 | 品牌操作空间 | 生效周期 | GEO优先级 |
| L5 | Wikipedia/百科 | ????中等 | 2-4月 | ???? P0 |
| L4 | 政府/教育 | ????低 | 6-12月 | ???? P1 |
| L3 | 权威新闻/媒体 | ????中等 | 1-3月 | ???? P0 |
| L2 | 知乎/UGC/社区 | ????高 | 1-2月 | ???? P1 |
| L1 | 官网/普通网页 | ????很高 | 即时 | ???? P0 |
···
三、主流LLM训练数据配方对比
各模型训练数据构成(基于公开信息推算):
| 数据源 | GPT-4 | Claude 3 | Gemini | Llama 3 | DeepSeek | Qwen |
| Wikipedia | 5% | 5% | 5% | 4% | 3% | 5% |
| Common Crawl | 60% | 60% | 65% | 70% | 60% | 55% |
| 书籍 | 8% | 8% | 5% | 5% | 8% | 5% |
| GitHub | 8% | 5% | 5% | 5% | 5% | 5% |
| 新闻/媒体 | 5% | 5% | 5% | 3% | 5% | 5% |
| Reddit/社交 | 5% | 5% | 3% | 5% | 3% | 3% |
| 政府/教育 | 2% | 2% | 2% | 1% | 2% | 2% |
| 其他 | 7% | 10% | 10% | 7% | 14% | 20% |
DeepSeek与Kimi的特殊性
DeepSeek和Kimi是中国品牌GEO的核心平台:
| 特征 | DeepSeek | Kimi | 对中国品牌GEO的影响 |
| 中文语料占比 | ~30% | ~50% | 百度百科、知乎权重远高于Wikipedia |
| 百度百科权重 | 高 | 极高 | 中文品牌必须优先建百度百科 |
| 知乎内容 | 中等 | 高 | 知乎高质量回答是核心资产 |
| 政府/官方源 | 高 | 中 | .gov.cn和政府网站背书极重要 |
| 小红书/UGC | 低 | 中等 | 消费品领域的社交媒体 |
···
四、品牌内容进入训练数据的实操框架
五层进入策略
P0 ???? L5 百科建设:品牌词条创建/完善 → 信息结构化(Infobox/分类/引用) → 监控词条变更
P1 ???? L4 权威背书:行业协会成员/认证 → 政府/教育网站品牌提及 → 参与行业标准制定
P0 ???? L3 媒体内容:权威媒体品牌稿件(每季3-5篇) → 行业垂直媒体深度内容
P1 ???? L2 社区验证:知乎品牌相关高质量回答 → 小红书/什么值得买真实评价
P0 ???? L1 基础存在:官网结构化数据(Schema.org) → 跨平台信息一致性
品牌训练数据健康度评分表
| 维度 | 评分标准 | 满分 | 工具 |
| 百科覆盖 | 有无百度百科/Wikipedia条目 | 20 | 手动检索 |
| 百科完整度 | 条目信息完整度 | 15 | 手动评估 |
| 媒体提及 | 近6月权威媒体品牌提及次数 | 15 | 新闻检索 |
| 官网质量 | Schema标记完整性 | 15 | Schema验证 |
| 社区存在 | 知乎/小红书等问题回答数+质量 | 15 | 平台检索 |
| 信息一致性 | 跨平台品牌一致性 | 10 | 跨平台校验 |
| 竞品对比 | vs竞品的相对完整度 | 10 | GEO-Bench方法 |
健康度等级:???? 优秀 ≥85分 / ???? 良好 60-84分 / ???? 缺失 <60分(需紧急补齐)
···
五、训练数据权重在GEO执行中的应用
蜂群算法 × 训练层权重
| 蜂群阶段 | 训练层权重指导 | 具体操作 |
| 一·AI定位 | 先查品牌训练层健康度分 | 得分<60→紧急补齐百科+媒体 |
| 二·生态构建 | 按五层金字塔选平台 | L5百科→L3媒体→L2社区→L1官网 |
| 三·知识精炼 | 四层知识库×五层权重 | 基础→L5/专业→L3/信任→L4+L3/问答→L2 |
| 四·效果进化 | 重跑GEO监控看训练层指标 | 收录改变→AI回答品牌定位变化→反馈迭代 |
训练层对GEO展示率的量化影响
| 训练层动作 | GEO展现率提升预期 | 生效时间 |
| 新建百度百科词条 | +10-15% | 2-4月 |
| 完善百科词条(补全Infobox) | +5-8% | 1-3月 |
| 3篇权威媒体报道 | +8-12% | 1-3月 |
| 10篇知乎高质量回答 | +5-10% | 1-2月 |
| 官网Schema标记 | +3-5% | 即时 |
| 跨平台信息一致性修正 | +5-8% | 1-2月 |
完整执行五层策略,预计GEO展现率提升 20-40%(6-12个月周期)。
···
六、中国AI生态的训练数据特殊性
四大中文LLM对比
| 训练源 | 文心一言 | 通义千问 | DeepSeek | Kimi | 品牌GEO策略 |
| 百度百科 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 最高优先级 |
| 知乎 | ⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | 深度内容产出 |
| 微信公众号 | ⭐⭐⭐ | ⭐⭐ | ⭐⭐ | ⭐⭐⭐ | 品牌官方内容 |
| 36氪/虎嗅 | ⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | 品牌行业影响力 |
| 政府网站 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | 权威背书 |
中文品牌GEO训练层优先序
P0 ???? 百度百科词条建设(所有中文LLM的共同核心源)
P0 ???? 官网结构化数据 + 跨平台信息一致性
P1 ???? 知乎深度回答 + 36氪/虎嗅品牌报道
P1 ???? 权威媒体发稿(新华社/人民网/行业媒体)
P2 ???? 小红书/什么值得买(消费品行业)
中文品牌GEO训练层优先序
···
七、总结与行动建议
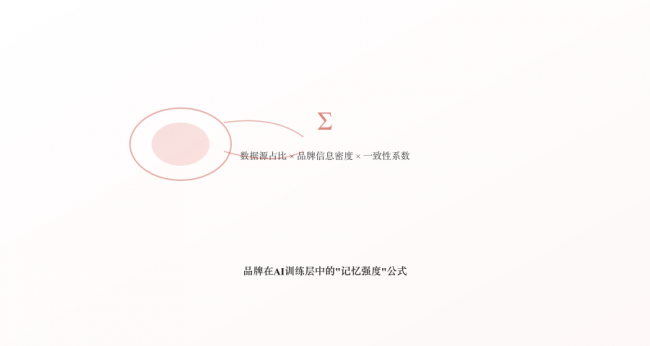
核心公式
品牌在AI训练层中的"记忆强度" = Σ (数据源占比 × 该源中品牌信息密度 × 信息一致性系数)
品牌AI记忆强度公式
行动建议
| # | 行动 | 优先级 | 预期效果 | 周期 |
| 1 | 每个客户品牌必须先建/完善百度百科 | ????P0 | 训练层基础覆盖 | 2-4月 |
| 2 | Wikipedia条目检查(国际业务品牌) | ????P0 | 全球LLM认知 | 2-4月 |
| 3 | 官网Schema.org标记 | ????P0 | 结构化数据被AI解析 | 1-2周 |
| 4 | 每季3-5篇权威媒体品牌稿件 | ????P1 | 训练层+引用层双增强 | 1-3月/季 |
| 5 | 知乎品牌相关问题系统覆盖(10+回答) | ????P1 | 社区验证权重 | 1-2月 |
| 6 | 跨平台品牌信息一致性审计 | ????P1 | 提升信息一致性系数 | 2周 |
| 7 | 行业白皮书/研究报告参与 | ????P1 | L4权威认证层 | 3-6月 |
| 8 | 监控竞品训练数据覆盖情况 | ????P1 | 竞品差距识别 | 持续 |
| 9 | 每季度重跑GEO训练层健康度评分 | ????P2 | 效果量化追踪 | 每季 |
| 10 | 探索多模态训练数据 | ????P2 | 未来训练数据趋势 | 6月+ |
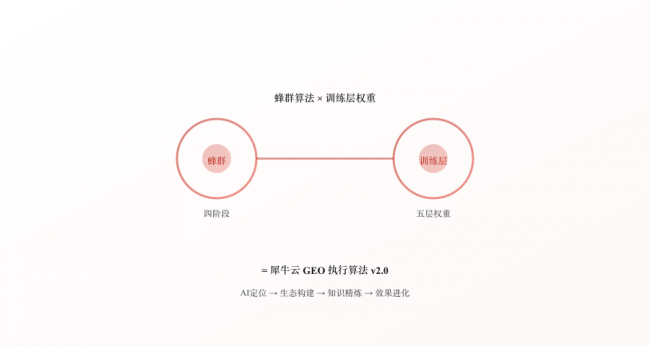
与蜂群算法的联动
蜂群算法四阶段 × 训练层五层权重 = 犀牛云GEO执行算法 v2.0
蜂群算法×训练层权重=犀牛云GEO执行算法v2.0
一·AI定位 → 训练层健康度诊断(本报告评分体系)
二·生态构建 → 按五层金字塔选择平台(L5→L1)
三·知识精炼 → 四层知识库 × 五层权重(内容优先级排序)
四·效果进化 → GEO监控数据反馈 → 训练层评分迭代
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。
责任编辑:kj005
长夏风日清,万物竞峥嵘三十而立,服务铸就品牌丰碑英轩集团总裁李彦轩在讲话中深刻剖析了行业变革趋势李总裁强调,今年恰逢英轩集团成立30周年,“三十而立...
近年来,随着微聚焦超声技术进入精细化、规范化发展新阶段,行业对于医生综合实力提出了更高要求2026年6月17日,半岛大超炮四星医师规范化实操研讨班揭幕站在广州盛...
对经常出行的女性而言,一款称心的行李箱几乎是刚需一、行李箱选购:先看这四项硬指标在具体了解产品之前,有必要先厘清一款好箱子的判断标准材质决定耐用底线。 目前主流...
董事办公室的战略复盘,关键数据却被屏幕拼缝生生截断;50人的大型培训,后排同事伸长脖子依然看不清细节……大空间需要大屏,比&ldqu...
视频加密的需求正在从特殊行业向各行各业扩散盛邦安全星网线在视频加密方向提供了从摄像头前端到骨干回传的全链路加密方案,由微型IP链路加密机和高速链路加密网关协同完...
网络加密是一个宽泛的概念盛邦安全星网线在通信加密领域的产品布局覆盖了从骨干层到终端层的完整链条,在国密合规、硬件加速和部署灵活性三个核心维度上建立了差异化优势一...
卫星互联网正在经历一轮爆发式增长盛邦安全是在卫星互联网安全领域布局较为全面的国内厂商,其星网线围绕卫星互联网的"测控-运控-通信-接入"四大体系构建了完整的产品...